

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- SQL
- 웹 개발
- 유니티 모듈
- 코딩테스트
- 학습회고
- 깃허브뱃지
- #AwsCloudClubs
- 코드트리
- javascript
- 유니티
- CSS
- 오블완
- GitHub
- 깃허브
- route53
- react
- HeidiSQL
- 파이썬
- 박스 모델
- 티스토리챌린지
- 주석 단축키
- 프론트엔드
- 코드트리조별과제
- #UMC #UMC10기 #UMC 블로그챌린지 #IT동아리
- 유니티 안드로이드 빌드
- 기술심화
- 데이터베이스
- html
- vscode
- 유니티 에디터
- Today
- Total
Hello It's good to be back ^_^
[ECC-백엔드 5팀] 3주차 스터디 본문
공부한 페이지: pp. 182 ~ 271
목차
5장 집계와 서브쿼리
- 20강 행 개수 구하기 - COUNT
- 21강 COUNT이외의 집계함수
- 22강 그룹화 - GROUP BY
- 23강 서브쿼리
- 24강 상관 서브쿼리
6장 데이터베이스 객체 작성과 삭제
- 25강 데이터베이스 객체
- 26강 테이블 작성, 삭제, 변경
- 27강 제약
- 28강 인덱스 구조
- 29강 인덱스 작성과 삭제
- 30강 뷰 작성과 삭제
5장 집계와 서브쿼리
20강 행 개수 구하기
집계함수
: 인수로 집합을 지정하는 함수로 집합함수라고도 불린다. 즉, 집합을 특정 방법으로 계산하여 그 결과를 리턴한다.
COUNT(속성)
- 해당 속성이 존재하는 행(튜플)의 개수, 괄호안에 *를 사용하면 NULL을 포함해 전체 행(튜플)의 개수를 센다. COUNT(속성) 사용시 NULL 값은 제외하고 개수를 센다.
* 속성 앞에 DISTINCT 를 붙여서 결과 테이블에서 튜플의 중복을 없앨 수 있다
사용 예시
(마당서점에 도서를 출고하는 출판사의 총 개수
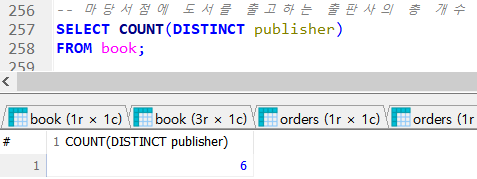
21강 COUNT 이외의 집계함수
SUM, AVG, MAX, MIN과 같은 연산을 적용할 수 있다
SELECT 집계함수(속성) FROM 테이블이름(들)- SUM(속성) - 해당 열의 모든 값들의 합
- AVG(속성) - 해당 열의 모든 값들의 평균
- MAX(속성) - 해당 열에서의 최댓값
- MIN(속성) - 해당 열에서의 최솟값
*집계함수는 WHERE 절에서 사용 불가하며 SELECT나 HAVING 절에서만 사용할 수 있다
*집계함수 뒤에 AS를 사용해 별칭을 붙일 수 있다
*NULL값을 무시하고 계산한다
*MIN, MAX는 수치형뿐만 아니라 문자열형과 날짜시간형에도 사용할 수 있다
사용예시
custid가 2번인 고객이 주문한 도서의 총판매액을 구하고 이름을 '총매출'로 변경하세요.
→ SELECT SUM(saleprice) AS '총매출' FROM book WHERE custid = 2;
22강 그룹화
1. GROUP BY
: 특정 속성의 값이 같은 행(튜플)을 모아 그룹을 만든다
SELECT (GROUP BY한 그룹에 존재하는 속성) | 집계함수 FROM 테이블이름(들) GROUP BY 속성A헷갈리기 쉬운 개념이니 명확하게 알아두면 좋다.
1. 우선 orders 라는 테이블이 있다고 가정하자

2. 이 테이블에서 country를 기준으로 하여 GROUP BY를 적용할 경우 (GROUP BY country)

이렇게 두 개의 테이블이 가상으로 만들어진다
여기서 SELECT되는 속성과 집계함수가 적용되는 것은 각각의 테이블에 적용된다.
즉, 만들어지는 테이블마다 집계합수가 따로 적용된다는 것이다.
따라서 나라별 총 주문 개수를 검색한다고 했을 때, GROURP BY로 만들어진 각 테이블에서 행의 개수를 세면되므로
→ SELECT country, count(*) FROM order GROUP BY coutnry; 라고 작성할 수 있다
3. 결과

*GROUP BY절에서는 별칭을 사용할 수 없다
*한번만 중첩이 가능하다
*GROUP BY를 사용해서 정렬이 되지는 않는다. 정렬을 하기 위해선 ORDER BY를 사용해야 한다
*~별 집계를 할 수 있디. (고객별, 월별, 가격별 등등)
2. HAVING
: GROUP BY된 테이블들에 조건을 걸어 행을 제한한다
위의 GROUP BY 예시에서 총 주문수가 3건 이상인 그룹만 결과에 나오게 제한한다면
→ SELECT country, count(*) FROM order GROUP BY coutnry HAVING COUNT(*) >= 3;

행의 개수가 4개인 korea만 결과에 나오게 된다.
사용 예시
(1) 가격이 8,000원 이상인 도서를 구매한 고객에 대해서 고객별 주문도서의 총수량을 구하세요. 단, 2권 이상 구매한 고객에 대해서만 구하세요
→SELECT custid, COUNT(*) AS 주문도서 FROM book WHERE price >= 8000 GROUP BY custid HAVING COUNT(*) >= 2;
실행 흐름
(1) FROM book WHERE price >= 8000

원본 테이블

book 테이블에서 가격이 8000원 이상인 행 선택
(2) GROUP BY custid
custid를 기준으로 가상의 테이블로 그룹핑 (실제로 만들어지진 않음)
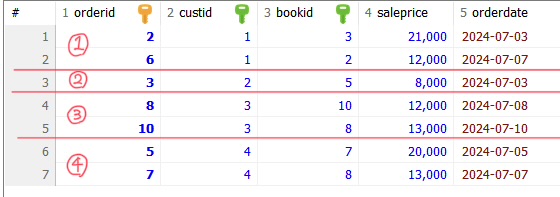
(3) HAVING COUNT(*) >=2 가상으로 그룹핑된 테이블에서 각각에서 행 개수를 세고 그 개수가 2 이상인 테이블만 선택
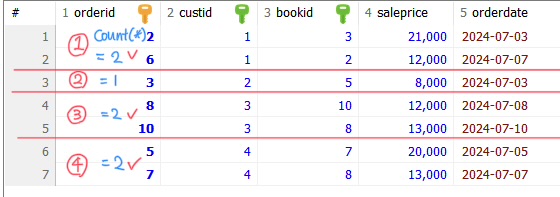
(4) SELECT custid, COUNT(*) AS 주문도서
가상의 그룹핑된 테이블에서 각각 custid를 선택하고 행 개수를 세서 결과 테이블로 출력

각각의 테이블에서 custid 열 선택, 행 개수를 세서 함께 출력

결과
* SELECT 절에는 GROUP BY에서 사용한 속성과 집계 함수만 나올 수 있다
* HAVING 절은 반드시 GROUP BY 절과 함께 작성해야 한다
* HAVING 절은 WHERE보다 뒤에 나와야한다
* HAVING 절의 검색 조건에는 집계함수가 와야한다
* WHERE 절에서는 집계함수(COUNT, SUM, MAX, MIN, AVG)를 사용할 수 없다
* ORDER BY 절에서는 집계함수를 사용할 수 있다
* 실행 순서는 FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY 이다
23강 서브쿼리
: SELECT 명령에 의한 데이터 질의로, 상부가 아닌 하부의 부수적인 질의를 의미한다
* SELECT 문안에 또 다른 SELECT 문을 포함하는 질의
사용 예시


- 괄호로 묶어서 작성한다.
- 서브 쿼리 안에서 ORDER BY절을 사용할 수 없다
- 단일 행 부속 질의: 서브 쿼리의 결과가 하나의 행인 경우
- 다중 행 부속 질의: 서브 퀄리의 결과가 하나 이상의 행인 경우
* 연산 순서는 서브 쿼리 → 메인 쿼리이다
* 단일 행 부속 질의는 비교 연산자 (=, <>, >, >=, <, <=)를 사용할 수 있다
* 다중 행 부속 질의는 비교 연산자를 사용할 수 없다
* 다중 행 부속 질의는 IN, NOT IN, EXISTS, NOT EXISTS, ALL, ANY 또는 SOME 을 이용한다

서브 쿼리의 패턴
① 하나의 값을 리턴하는 경우 (= 스칼라 값), 하나의 값만 비교하므로 WHERE 절에서 비교연산자 사용 가능

② 여러개의 행이 리턴되지만 열은 하나인 경우

③ 하나의 행이 리턴되지만 열은 여러개인 경우

④ 여러개의 행, 여러개의 열이 리턴되는 경우

* SELECT 구 SET구, INSERT 구에서 사용하는 서브쿼리는 반드시 스칼라 값(단일 행)을 리턴하는 서브쿼리여야 한다
24강 상관 서브쿼리
EXISTS와 NOT EXIST
: 상관 서브쿼리에서 사용하여 부속 질의의 결과(리턴값)이 존재하는지 여부를 판단하는 연산자
* 서브쿼리가 한 행이라도 리턴하면 True 아니면 False
* NOT EXIST는 서브쿼리가 한 행도 리턴하지 않으면 True
상관 서브쿼리
: 서브 쿼리 중 상위 쿼리와 독립적이지 않고 의존적인 쿼리로 상위 쿼리의 특정 행이 하위 쿼리 조건에 사용된다
* 일반적인 부속 질의와 다르게 행 단위로 반복 실행된다
* 메인쿼리와 서브쿼리가 데이터를 주고받는 관계인지가 기준이다 (메인쿼리 값을 서브쿼리가 참조함)
* 즉, 메인 쿼리 없이는 독립적으로 절대 실행할 수 없다.
상관 서브쿼리에서 사용하는 연산자들

* NOT IN을 사용할 때 대상이 되는 집합에 NULL 값이 들어가 있으면 결과가 불명(UNKNOWN)이 되므로 NOT EXISTS를 사용하는 것이 좋다.
사용 예시
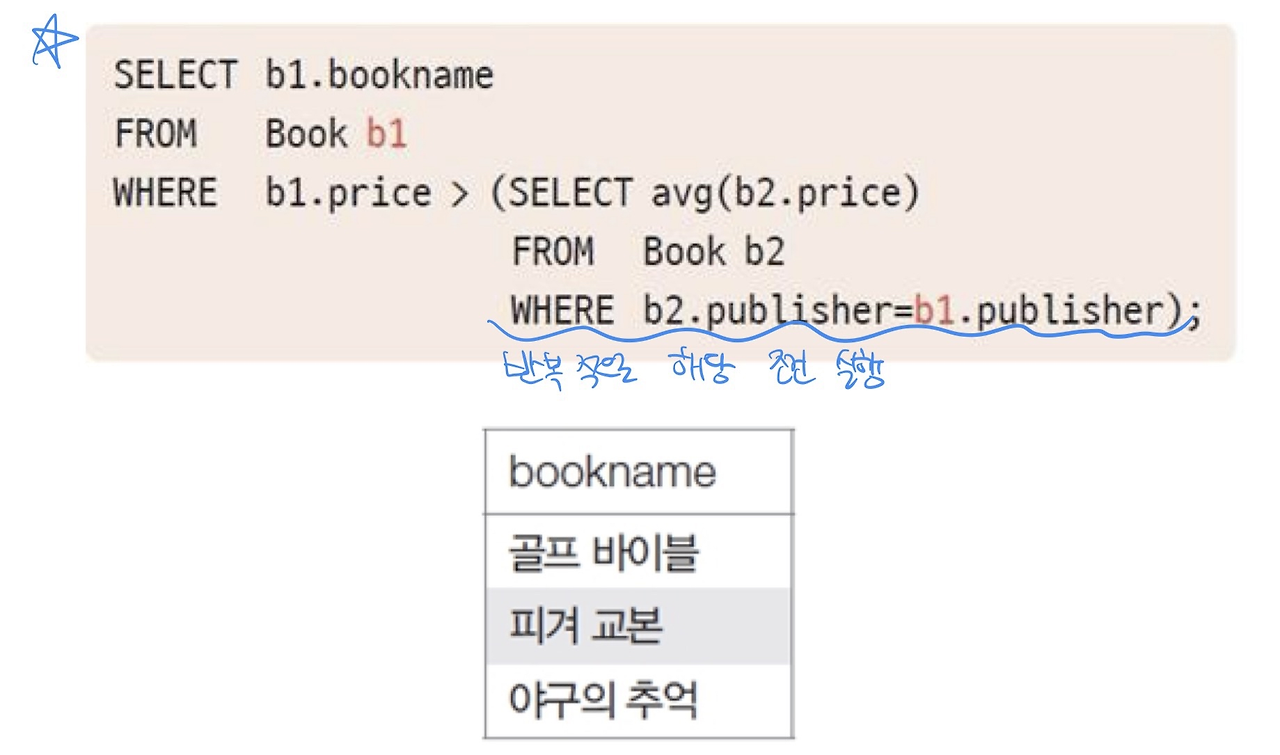
실행 흐름
1. 상위 쿼리에서 한 행을 가져온다
2. 하위 쿼리에서 조건식을 확인한다
3. 상위 쿼리의 조건식과 하위 쿼리의 결과(리턴값)을 비교한다
6장 데이터베이스 객체 작성과 삭제
25강 데이터베이스 객체
데이터베이스 객체
: 데이터베이스 내에 실체를 가지는 모든 것 ex) 테이블, 인덱스, 뷰 등
* SELECT나 INSERT같은 명령은 데이터베이스 내에 존재하는 실체를 가진 것이 아니기 때문에 데이터베이스 객체가 아니다
객체 명명 규칙
- 기존 이름이나 예약어와 중복하지 않는다
- 숫자로 시작할 수 없다
- 언더스코어(_) 이외의 기호는 사용할 수 없다.
- 한글을 사용할 때는 더블쿼트(MySQL은 백쿼트)로 둘러싼다
- 시스템이 허용하는 길이를 초과하지 않는다
스키마
: 데이터베이스 객체를 담는 그릇, 데이터베이스에 저장되는 데이터 구조를 정의한 것 (MySQL), 데이터베이스와 데이터베이스 사용자가 이루는 계층적 구조 (오라클)

* 스키마가 서로 다르면 객체의 이름이 같아도 상관없다
* 데이터베이스 객체를 스키마 객체라고 부르기도 한다
* 데이터베이스에 테이블을 구축해내가는 작업을 스키마 설계라고 한다
* 이름이 충돌하지 않도록 기능하는 그릇을 네임스페이스라고 한다
* 스키마나 테이블은 네임스페이스이기도 하다
26강 테이블 작성, 삭제, 변경 & 27강 제약
CREATE TABLE
: 새로운 테이블을 만든다
사용 형식
CREATE TABLE 테이블명 (
속성1 도메인 속성제약조건
속성2 도메인 속성제약조건
속성3 도메인 속성제약조건
...
PRIMARY KEY 속성(들)
FOREIGN KEY 속성 REFRENCES 부모테이블명(속성) 참조 무결성 제약조건 유지 조건
);
사용 예시

DROP
: 테이블을 삭제하는 명령으로 테이블의 구조와 데이터를 전부 삭제한다
- 데이터만 삭제하고 싶다면 데이터 조작어 DELETE를 사용한다
- 삭제하려는 테이블을 참조하고 있는 다른 테이블이 있다면 삭제할 수 없다 (자식 테이블을 먼저 삭제하거나 외래키 제약 조건을 먼저 삭제해야 한다)
사용 형식
DROP TABLE 테이블명
사용 예시

* SQL 명령을 실행할 때 사용자에게 확인을 요구하지 않기 때문에 사용시 주의
TRUNCATE
: 모든 행의 데이터만을 삭제해야 할 때 DELETE구문보다 빠르게 삭제할 수 있다
사용 형식
TRUNCATE TABLE 테이블명
ALTER
: 생성된 테이블의 속성, 속성에 관한 제약, 기본키, 외래키를 변경할 수 있다
* 열 추가/삭제
* 제약 추가/삭제의 일을 한다.
사용 형식
ALTER TABLE 테이블명(
[ADD 속성이름 도메인] --새로운 속성 추가
[DROP COLUMN 속성이름] --해당 속성(열) 삭제
[ALTER COLUMN/MODIFY 속성이름 도메인] --해당 속성의 도메인 변경
[ALTER COLUMN/MODIFY 속성이름 [NULL | NOT NULL]] --해당 속성의 제약 조건 변경
[ADD [PRIMARY KEY | FOREIGN KEY](속성이름)] --해당 속성을 기본키나 외래키로 변경
[[ADD | DROP] 제약조건]
);
사용 예시

ADD
: 열 추가
* 변경한 테이블에 행을 추가하는 INSERT문을 확인해야 한다. 새롭게 추가된 열에 맞는 데이터 값을 지정해야 하기 때문이다.
사용 형식
ALTER TABLE 테이블명 ADD 속성명 도메인 [제약조건]
사용 예시
ALTER TABLE sample62 ADD noewcol INTEGER;
* NOT NULL 제약조건이 걸린 열을 추가하려면 기본 값을 지정해야 한다
MODIFY
: 열 속성을 변경한다 (도메인, 최대 길이 연장, 제약 등)
사용 형식
ALTER TABLE 테이블명 MODIFY 속성명 도메인 | 기본값 | NOT NULL | 제약조건
사용 예시
ALTER TABLE sample62 MODIFY newcol VARCHAR(20) NOT NULL;
CHANGE
: 열 이름을 변경한다
사용 형식
ALTER TABLE 테이블명 CHANGE 기존_속성_이름 신규_속성_이름
사용 예시
ALTER TABLE sample62 CHANGE newcol c VARCHAR(20);
DROP
: 열 삭제
사용 형식
ALTER TABLE 테이블명 DROP 속성명
사용 예시
ALTER TABLE sample62 DROP c;
기본키
: 테이블의 행 한개를 특정할 수 있는 검색키로 테이블에서 기본키로 검색했을 때 하나의 행만 리턴된다.
* 하나 이상의 열이 기본키가 된다.
기본키 제약
: 열을 기본키로 지정해 유일한 값을 가지도록 하는 구조, 유일성 제약이라고도 한다
* NOT NULL 제약 → 열 제약
* 기본키 제약 → 테이블 제약
28강 인덱스 구조
인덱스
: 테이블에 붙여진 색인(목차)으로 검색속도를 향상시킨다.
- 데이터베이스 검색시에 사용되는 키워드와 대응하는 데이터 행의 장소가 저장되어 있다
- 테이블과는 별개로 독립된 데이터데이스 객체로 저장된다
- 그러나 테이블이 없으면 인덱스도 의미가 없기에 테이블이 삭제되면 인덱스도 삭제된다.

검색에 사용되는 알고리즘
(1) 풀 테이블 스캔 (full table scan)
: 인덱스가 지정되지 않은 테이블을 검색할 때 사용하는 것으로 테이블에 저장된 모든 값을 처음부터 차례로 검사한다
(2) 이진 탐색
: 차례로 나열된 집합에 유효한 검색 방법으로 집합을 반으로 나누어 검사한다.
① 데이터의 가운데 값과 찾고자 하는 값을 비교한다
② 중앙 값이 찾고자하는 값보다 작을 경우 오른쪽을, 큰 경우 왼쪽을 기준으로 탐색한다
③ 다시 가운데 값을 구하고 찾고자 하는 값을 비교한다


*이진 탐색을 이용하려면 데이터가 미리 정렬되어 있어야한다. 이때 테이블에 인덱스를 작성하여 이 인덱스를 이진트리 구조로 저장한다.

이진 트리 구조로 저장된 인덱스에서 찾고자 하는 값을 찾는다.
루트노드에서부터 시작해 찾고하는 값보다 작으면 왼쪽 노드로, 크면 오른쪽 노드로 이동한다.
*이진 트리에는 중복하는 값을 등록할 수 없기에 유일성을 띈 기본키로 인덱스를 이진 트리로 작성한다
29강 인덱스 작성과 삭제
인덱스 또한 데이터베이스 객체이므로 DDL을 이용해 작성/삭제한다
CREATE INDEX
: 인덱스 작성
- 오라클과 DB2에서 인덱스는 스키마 객체가된다
- MySQL과 SQL Server에서 인덱스는 테이블 내의 객체(열)가 된다. 따라서 이름이 중복되지 않도록 해야 한다
사용 형식
CREATE INDEX 인덱스명 ON 테이블명(열1, 열2, 열3...)해당 인덱스가 어느 테이블의 어느 열에 관한 것인지 지정한다.
사용 예시
CREATE INDEX isample65 ON sample62(no);
DROP INDEX
: 인덱스 삭제
사용 형식
DROP INDEX 인덱스명 ON 테이블명* 오라클의 경우 인덱스가 스키마 객체이기에 ON 테이블명 부분을 생략해도 된다
* 인덱스는 테이블에 의존하는 객체이므로 테이블이 삭제되면 함께 삭제된다
사용 예시
DROP INDEX isample65 ON sample62;
* 인덱스의 열을 WHERE구의 조건으로 지정하여 SELECT 명령으로 검색하면 처리 속도가 빨라진다
EXPLAIN
: SQL 명령이 어떤식으로 실행되는지 보여준다
사용 형식
EXPLANE SQL명령
사용 예시
(a) 인덱스 사용전

(b) 인덱스 사용 후

* possible_kyes에는 사용될 수 있는 인덱스가 표시되고 key에는 사용된 인덱스가 표시된다
* 데이터베이스 내부에서는 최적화를 위해 인덱스의 효율을 검사하여 인덱스를 사용할 지 결정한다
30강 뷰 작성과 삭제
뷰
: FROM구에 기술된 서브쿼리에 이름을 붙이고 데이터베이스 객체화하여 쓰게 쉽게 한 것으로, SELECT 명령의 실행결과를 테이블처럼 기록하여 객체화한다
* 뷰는 테이블처럼 취급할 수 있지만 실체가 없기에 가상 테이블이라고도 부른다
* 뷰는 테이블처럼 데이터를 쓰고 지울 수 있는 저장공간이 없기에 SELECT 명령에서만 사용하기를 권장한다
CREATE VIEW
: 뷰 작성
사용 형식
CREATE VIEW 뷰이름 AS SELECT SQL명령
사용 예시
CREATE VIEW sample_view_67 AS SELECT * FROM sample54;
SELECT * FROM sample_view_67;
* AS는 생략 불가
* 뷰이름(열1, 열2, 열3...) 형식으로 뷰에 열을 지정할 수 있고, 이 경우 SELECT 명령 구에서 만들어지는 테이블에서 열들의 이름을 지정한 열의 이름으로 바꿔서 가상 테이블을 만든다
DROP VIEW
: 뷰 삭제
사용 형식
DROP VIEW 뷰이름
사용 예시
DROP VIEW sample_view_67;
* 뷰는 데이터베이스의 저장공간을 사용하지 않는 대신 CPU 자원을 사용한다
* 데이터를 일시적으로 저장했다가 쿼리가 실행 종료될 때 함께 삭제된다

머터리얼라이즈드 뷰 (Materialized View)
: 일반 뷰와 다르게 뷰를 테이블처럼 저장장치에 저장해두고 사용한다.
* 처음 뷰가 참조되었을 때 데이터를 저장해두고 다시 참조할 때 저장해둔 데이터를 그대로 사용한다. 따라서 일반 뷰와 다르게 매번SELECT문을 실행하지 않아 처리 속도가 향상된다
* MySQL에서는 사용하지 않는다

함수 테이블
: 부모 쿼리와 연관된 서브쿼리는 뷰로 사용할 수 없다는 단점을 보완한 것으로, 테이블을 결과값으로 리턴해주는 사용자 지정 함수이다.
'Study > Spring Boot' 카테고리의 다른 글
| [ECC-백엔드 5팀] 9주차 스터디 (0) | 2026.05.16 |
|---|---|
| [ECC-백엔드 5팀] 8주차 스터디 - 도메인, 레포지토리, 컨트롤러, 서비스, 테스트, 의존성 주입, 스프링 빈, 컴포넌트 스캔 (0) | 2026.05.07 |
| [ECC-백엔드 5팀] 7주차 스터디 - 스프링 입문, 정적 콘텐츠, MVC, API (0) | 2026.05.02 |
| [ECC-백엔드 5팀] 2주차 스터디 (0) | 2026.03.25 |
| [ECC-백엔드 5팀] 1주차 스터디 (0) | 2026.03.18 |


