
Hello It's good to be back ^_^
파이썬 머신러닝 스터디 1주차 (ch01 넘파이와 판다스) 본문
교재: 파이썬 머신러닝 완벽 가이드
공부한 페이지 : 1p~84p
실습한 내용: https://github.com/HongYeonLee/Pylot_MachineLearningStudy
GitHub - HongYeonLee/Pylot_MachineLearningStudy
Contribute to HongYeonLee/Pylot_MachineLearningStudy development by creating an account on GitHub.
github.com
머신러닝
머신러닝의 개념
- 애플리케이션을 수정하지 않고도 데이터를 기반으로 패턴을 학습하고 결과를 예측하는 알고리즘
- 머신러닝 = 데이터 + 머신러닝 알고리즘 (중요성은 데이터 >>>> 머신러닝 알고리즘)
- ex) 금융 사기 거래 적발 프로그램, 스팸메일 필터링 프로그램, 데이터 마이닝, 영상 인식, 음성 인식, 자연어 처리 등
머신러닝의 분류
-지도학습 (분류, 회귀)
-비지도학습
머신러닝의 대표 패키지
- 사이킷런(Scikit-Learn)
- 넘파이(NumPy)(선형대수를 다룸)
- 판다스(Pandas)(데이터 핸들링)
넘파이(Numerical Phython, Numpy)
ndarry - 넘파이의 기본 데이터 타입 (배열과 비슷한 개념)
넘파이의 기본 api
- import numpy as np - 넘파이 모듈 임포트
- np.array(배열) - 배열을 ndarray로 변환해준다
- ndarray.shape - ndarray의 행, 열을 순서쌍으로 알려준다
- ndarray.ndim - ndarray의 차원을 알려준다
- ndarray.astype('데이터형') - 원하는 데이터형으로 원소들의 데이터를 형변환해준다
- ndarray = np.arange(정수) - 0부터 (정수 -1)까지의 정수들로 이루어진 ndarray를 만들어준다
- ndarray = np.arange(start = 1, stop = 10) - 1부터 9까지의 정수들로 이루어진 ndarray 생성
- ndarray = np.zeros((행, 열), dtype = '데이터타입') - 0으로 초기화된 크기 행x열의 ndarry 생성
- ndarray = np.ones((행, 열), dtype = '데이터타입') - 1로 초기화된 크기 행x열의 ndarry 생성
- ndarray.reshape(행, 열) - 기존의 ndarray를 원하는 행x열로 바꿔준다. 단, 원소의 개수와 행x열의 수가 맞아야 한다
- ndarray.reshape(행, 열)에서 행, 열에 -1을 넣으면 행과 열 둘중에 맞게 자동 변환을 해준다
- ndarray.tolist() - ndarray를 list로 변환해준다
ndarray의 데이터 타입
- int형, unsigned int형, float형, complex 타입
- 정수로 이루어진 list를 ndarray로 변환할시 데이터값들은 전부 int32형이 된다
- 서로 다른 데이터형들이 있을 수 없으며 만약 있을시 더 큰 데이터 타입으로 형 변환이 된다
넘파이의 인덱싱 api
-단일 데이터 추출
- 1차원 ndarray[인덱스] - 인덱스에 해당하는 데이터 값을 추출, -1을 넣으면 제일 맨 뒤의 데이터 값을 의미
- 2차원 ndarray[행, 열] - 행, 열에 해당하는 데이터 값 추출
- 2차원 ndarray에서 axis 0 (상 -> 하 방향)은 행을 의미
- 2차원 ndarray에서 axis 1 (좌 -> 우 방향)은 열을 의미
-슬라이싱
- 1차원 ndarray[시작인덱스 : 종료인덱스] - 시작인덱스부터 (종료인덱스 -1)까지에 해당하는 데이터 값 추출
- 시작인덱스 생략시 처음 인덱스인 0으로 간주
- 종료인덱스 생략시 마지막 인덱스로 간주
- 인덱스를 모두 생략할 수도 있다 (이 경우 ndarray의 전체 데이터 값 추출)
- 2차원 ndarray[행의 시작인덱스 : 행의 종료인덱스, 열의 시작인덱스 : 열의 종료인덱스] - [행, 열]로 해석하여 시작인덱스부터 (종료인덱스 - 1)까지의 데이터 값 추출
ex)
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
위의 표와 같은 3x3의 ndarray형 array1이 있다고 해보자
array1[0:2, 0:2]는 0행부터 1행까지, 0열부터 1열까지로 array1을 슬라이싱해 해당하는 데이터 값을 추출한다는 뜻이다
따라서 추출되는 데이터 값은 다음 표와 같이 된다.
| 1 | 2 |
| 4 | 5 |
- 2차원 ndarray[정수] - 정수에 해당하는 행의 ndarray만 리턴, 따라서 1차원 ndarray를 리턴
-팬시 인덱싱
크게 중요하지 않으므로 사진으로 설명을 대체한다

-불린 인덱싱 (Bollean indexing)
- 1차원 ndarray[ndarray 조건식] - 해당 조건식에 맞는 데이터 값만 추출
- ex) array1d[array1d > 5] - 5보다 큰 데이터 값만 추출
- 조건식에 맞지 않으면 false, 맞으면 true를 리턴하고 true값을 가진 인덱스를 저장한다
넘파이의 행렬 정렬 api
- np.sort(ndarray) - 원본 행렬을 그대로 유지한채 원본 행렬의 정렬된 행렬을 리턴
- ndarray.sort() - 원본 행렬을 정렬된 형태로 변환하고 리턴값은 없다
- 기본적으로 오름차순으로 정렬하며 내림차순으로 정렬할시
- np.sort(ndarray)[::-1] 이나 ndarray.sort()[::-1] 이라 적는다
- np.sort(ndarray, axis = 0) 행 방향 (상 -> 하) 으로 내림차순 정렬
- np.sort(ndarray, axis = 1) 열 방향 (좌 -> 우) 으로 내림차순 정렬

- np.argsort(ndarray) - 원본 행렬이 정렬되었을 때, 정렬 되기 전 원소의 인덱스를 ndarray 형태로 리턴
- ex) 원본 행렬 [3, 1, 9, 5] -> 정렬 행렬 [1, 3, 5, 9] -> 원본 행렬의 원소들의 인덱스는
- 3의 인덱스는 0, 1의 인덱스는 1, 9의 인덱스는 2, 5의 인덱스는 3이다
- 이를 정렬 행렬의 적용하면 1 0 3 2 이다 (정렬된 행렬의 원본 행렬 인덱스 반환)

넘파이의 선형대수 연산 api
- np.dot(ndarry1, ndarry2) - 행렬 ndarray1과 ndarry2의 행렬 내적을 계산해준다
- np.transpose(ndarray) - 행렬 ndarray의 transpose를 구해준다
판다스 (Pandas)
DataFrame - 판다스의 기본 객체
2차원 크기이고 엑셀의 형태라고 생각하면 쉽다
특이한 점은 행을 인덱스로, 열을 칼럼명으로 생각해야 한다는 점이다.
Kaggle에서 머신러닝에 사용하기 좋은 다양한 데이터 파일을 제공한다
판다스의 기본 api
- import pandas as pd - 판다스 모듈 임포트
- 특정 파일을 읽어 DataFrame으로 만들 수 있다
- pd.read.csv(r'파일경로) or 주피터 노트북이 있는 디렉토리에 .csv(칼럼을 ,로 구분한 파일 포맷) 파일이 있다면
- pd.read.csv('파일명.csv') 를 사용해 csv 파일을 DataFrame으로 만들 수 있다
- DataFrame - 입력하는 것만으로 엑셀 파일과 같은 데이터를 불러온다

- DataFrame.head() - DataFrame의 맨 앞에 있는 N개의 행을 리턴한다, default는 5개
- DataFrame.info() - 총 데이터 건수, 데이터 타입, Null 건수을 보여준다 (object형은 문자열 타입이라 생각하면 된다)
- DataFrame.describe() - 오직 숫자형 데이터의 건수, 평균, 표준편차, 최소값, 20%값, 50%값, 75%값, max값을 보여준다
- DataFrame.['칼럼명'] - Series(칼럼이 하나뿐인 데이터 구조체)형태로 특정 칼럼의 데이터를 보여준다
- DataFrame.['칼럼명'].value_counts() - 특정 칼럼의 데이터 분포도를 보여준다
- DataFrame.[['칼럼명1', '칼럼명2',....]] - 여러개도 가능

- .value_counts() 메소드는 Null값은 무시하고 내놓는다
- Null 값을 포함해 데이터 건수를 확인하고자 하면 .value_count(dropna = False) 를 이용하면 된다
파일없이 DataFrame 만드는 법

- 변수명 = {'칼럼명': [칼럼명에 해당하는 데이터 값들]}
- pd.DataFrame(변수명, index = [인덱스로 지정할 데이터 값들])
리스트, 딕셔너리, 넘파이 ndarray -> DataFrame 변환 api
- pd.DataFrame(1차원 list or ndarry, columns = '컬럼명') - 1차원 list나 ndarray를 DataFrame으로 변환
- pd.DataFrame(2차원 list of ndarry. columns = 컬럼명을 원소로 가지는 리스트) - 2차원을 변환하는데 여기서 열의 개수만큼 컬럼명이 있어야 한다.
- 딕셔너리의 키(key)는 칼럼명으로, 값(value)은 키에 해당하는 데이터로 변환

DataFrame -> 리스트, 딕셔너리, 넘파이 ndarray 변환 api
- DataFrame.values - DataFrame을 ndarry로 변환
- DataFrame.vlaues.tolist() - DataFrame을 list로 변환
- DataFrame.to_dict('list') - DataFrame을 딕셔너리로 변환
DataFrame의 칼럼 데이터 세트 생성과 수정 api
- DataFrame['추가할 칼럼명'] - DataFrame에 새로운 칼럼을 추가한다. 특정 데이터 값으로 초기화도 가능하다

- 칼럼의 데이터 값을 수정하기 위해 연산을 할 수도 있다

DataFrame 데이터 삭제 api
- DataFrame.drop(labels = None, axis = 0, index = None, columns = None, level = None, inplce = False, errors = 'raise')
- 인자를 전부 적지 않아도 된다. 주로 사용하는 것은 labels, index, columns, inplace
- 행을 삭제하고 싶으면 axis = 0, 열을 삭제하고 싶으면 axis = 1
- inplace의 default는 false인데, false는 원본 DataFrame은 유지하고 수정된 DataFrame을 리턴한다
- inplace = True 일때는 원본 DataFrame의 데이터 값을 직접 수정하고 None을 리턴한다
- ex) DataFrame.drop('칼럼명', axis = 1) - 해당 칼럼을 삭제한 DataFrame을 리턴하되 원본은 그대로 수정되지 않는다
- DataFrame.drop(['칼럼명1', '칼럼명2', ...., axis = 1)의 형태로 여러 칼럼을 삭제할 수도 있다
판다스의 Index 객체
- 변수명 = DataFrame.index - index 객체 추출
- 변수명.values - index 객체를 실제 값 array로 변환
- 한번 만들어진 DataFrame 및 Series의 Index 객체는 함부로 변경할 수 없다
- Index는 오로지 식별용으로만 사용된다
- DataFrame.reset_index() or Series.reset_index() - 0에서 부터 시작하는 새로운 index 칼럼이 추가된다
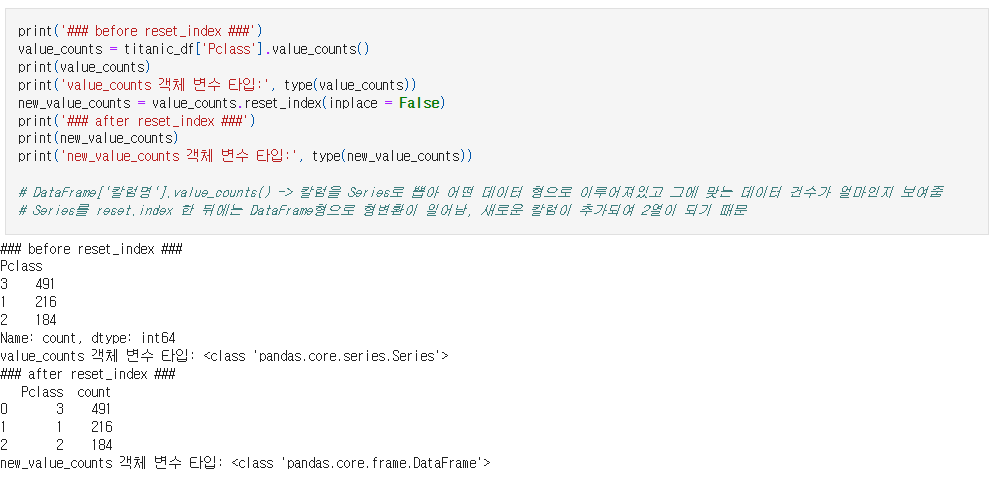
### after reset_index ###
Pclass count
0 3 491
1 1 216
2 2 184
- 위의 사진과 같이 Pclass 왼쪽에 새로운 인덱스 0, 1, 2...가 추가된 걸 볼 수있다
데이터 셀렉션 및 필터링 api
- DataFrame[DataFramep['칼럼명'] 조건식] - 불린(Boolean) 인덱싱 기능, 조건식에 맞는 칼럼의 특정 데이터 값만 보여준다
- [ ]안의 인자는 칼럼명(또는 칼럼명을 원소로 하는 리스트)을 지정해 칼럼 지정 연산에 사용하거나 불린 인덱스 용도로만 사용해야 한다
DataFrame iloc[ ] 연산자
- DataFrame.iloc[행, 열] - 위치 기반 인덱싱으로 인자는 정숫값 또는 정수형 슬라이싱, 팬시 리스트 값을 입력해야 한다
- 해당 행, 열에 맞는 데이터 값을 추출한다
- DataFrame.iloc[:, -1] - 맨 마지막 칼럼의 값을 가져온다
- DataFrame.iloc[:, :-1] - 처음부터 맨 마지막 칼럼을 제외한 모든 칼럼을 가져온다
- .lioc은 불린 인덱싱을 제공하지 않는다
DataFrame loc[ ] 연산자
- DataFrame.loc['인덱스', '칼럼명'] - 명칭(label) 기반 인덱싱, '인덱스'에는 정수가 들어갈 수 있으나 사용자가 지정한 인덱스와 다르면 오류가 발생하니 주의
- DataFrame.loc[시작행렬:마지막행렬, '칼럼명'] - 슬라이싱 인덱싱이 가능하나 범위는 시작행렬 ~ 마지막행렬이다 (마지막행렬 -1 이 아님을 주의), 이는 loc가 명칭 기반 인덱싱이기에 숫자가 아니라 명칭이기에 -1을 할 수 없기 때문이다
- loc[]은 iloc[]와 다르게 불린 인덱싱이 가능하다
팁 - 칼럼 값의 '전체'를 추출할 때는 DataFrame['칼럼명']과 같이 사용한다. 칼럼 값의 '부분'을 추출할 때는 iloc[ ]나 loc[ ]를 사용한다
판다스의 불린 인덱싱
- DataFrame[DataFrame['칼럼명'] 조건식] - 조건식에 맞는 칼럼이 리턴된다
- DataFrame[DataFrame['칼럼명'] 조건식][['칼럼명1', '칼럼명2',...]] - 조건식에 맞는 데이터의 원하는 칼럼을 별도로 추출할 수 있다

- DataFrame.loc[DataFrame['칼럼명'] 조건식, ['칼럼명1', '칼럼명2',...]] - loc[ ]를 이용해서도 동일한 작업을 할 수 있다
- &, |, ~을 이용한 여러 복합 조건도 가능하다

- 조건을 변수에 할당해서도 사용할 수 있다

정렬, Aggregation 함수, GroupBy 적용
정렬
- DataFrame.sort_values(by, ascending, inplace) - DataFrame을 정렬한다
- by = ['칼럼명'] - 해당 칼럼을 정렬한다, 리스토 작성하여 여러개의 칼럼을 정렬할 수도 있다
- ascending = True or False - True는 오름차순, False는 내림차순 정렬, default는 오름차순이다
- inplce = True or False - True는 원본 DataFrame에 직접 정렬을 하고 False는 정렬된 DataFrame을 리턴한다
Aggregation
- DataFrame에 min(), max(), sum(), count()을 적용하는 함수를 Aggregation이라 한다
- DataFrame.count() - 모든 칼럼의 해당하는 데이터 건수를 리턴한다, Null값은 반영하지 않는다
- DataFrame[['칼럼명1', '칼럼명2]].mean() - 특정 칼럼에 해당하는 데이터들의 평균 리턴
GroupBy
- GroupBy는 by 뒤에 오는 것이 인덱스가 되어 정렬한다고 이해하면 쉽다
- DataFrame.groupby(by = '칼럼명') - 해당 칼럼을 기준으로 Groupby

- DataFrame.groupby('칼럼명')[['칼럼명1', '칼럼명2',....]] - '칼럼명'을 인덱스로 작용하여 정렬하고 원하는 '칼럼명1', '칼럼명2',...에 해당하는 데이터를 보여준다

- 위 사진을 기준으로 설명하면 1등석 손님이 216명, 2등석 손님이 184명, 3등석 손님이 491명임을 보여준다
- DataFrame.groupby('칼럼명')['칼럼명1'].agg() - 칼럼명의 인덱스에 해당하는 데이터들의 agg값을 보여준다

- DataFrame.groupby('칼럼명').agg({'칼럼명1':'적용할agg', '칼럼명2':'적용할agg',....) -딕셔너리 형태로 agg가 적용될 칼럼들과 적용될 agg함수를 입력한다, 칼럼명을 기준으로 정렬된 데이터들이 칼럼명의 인덱스별로 agg가 적용된다

결손 데이터(Null)를 처리하는 api
-Null은 넘파이에서 NaN으로 표시한다
- DataFrame.isna() - Null데이터가 있으면 True, 없으면 False로 리턴한다
- DataFrame.isna().sum() - True는 1로, False는 0으로 리턴되므로 합계를 구해 결손 데이터의 개수를 구할 수 있다
- DataFrame['칼럼명'].fillna('대체 하고자 하는 것'] - 해당 칼럼명에 있는 결손 데이터를 원하는 인자로 대체할 수 있다
- fillna()에 inplace = True를 적용해야 원본 DataFrame에도 대체가 적용된다
apply lambda 식으로 데이터 가공
lambda는 한 줄짜리 함수라고 이해하면 쉽다
- lambda 입력인자 : return 값
- ex) 제곱을 구하는 함수 - lambda x : x ** 2
- : 을 기준으로 왼쪽은 입력 인자, 오른쪽은 return 값이다
- map(lambda 입력인자 : return, 여러개의 입력인자들) - 여러개의 입력 인자를 사용할 때는 map() 함수를 결합한다
- DataFrame['칼럼명'].apply(lambda 입력인자 : return 값))

- DataFrame['칼럼명'].apply(lambda 입력인자 : 리턴값 if 조건식 else 리턴값) - if 조건식이 맞으면 if 앞의 리턴값이 리턴되고 else 조건식이 맞으면 else 뒤의 리턴값이 리턴된다
- if, else만 지원되고 else if 는 지원하지 않는다
'Study > 파이썬 머신러닝' 카테고리의 다른 글
| 파이썬 머신러닝 스터디 6주차 (ch06 차원 축소) (0) | 2024.05.08 |
|---|---|
| 파이썬 머신러닝 스터디 5주차 (ch05 회귀) (0) | 2024.05.04 |
| 파이썬 머신러닝 스터디 4주차 (ch04-2 분류) (0) | 2024.04.11 |
| 파이썬 머신러닝 스터디 3주차 (ch04-1 분류) (2) | 2024.04.04 |
| 파이썬 머신러닝 스터디 2주차 (ch03 평가) (1) | 2024.03.28 |



