
Hello It's good to be back ^_^
파이썬 머신러닝 스터디 4주차 (ch04-2 분류) 본문
교재: 파이썬 머신러닝 완벽 가이드
공부한 페이지 : 221p~307p
실습한 내용: https://github.com/HongYeonLee/Pylot_MachineLearningStudy
GitHub - HongYeonLee/Pylot_MachineLearningStudy
Contribute to HongYeonLee/Pylot_MachineLearningStudy development by creating an account on GitHub.
github.com
목차
05. GBM(Gradient Boosting Machine)
06. XGBoost(eXtra Gradient Boost)
07. LightGBM
08. 베이지안 최적화 기반의 HyperOpt를 이용한 하이퍼 파라미터 튜닝
09. 분류 실습 - 캐글 산탄테르 고객 만족 예측
10. 분류 실습 - 캐글 신용카드 사기 검출
11. 스태깅 앙상블
05. GBM(Gradient Boosting Machine)
부스팅 알고리즘
- 여러 개의 약한 학습기를 순차적으로 학습하면서 잘못 예측한 데이터에 가중치를 부여해 오류를 개선해 나가면서 학습하는 것을 말한다
- AdaBoost(Adaptive Boost)와 GBM(Gradient Boosting Machine)가 있다
AdaBoost
- 오류 데이터에 가중치를 부여하면서 부스팅을 수행한다

- 동그라미 표시가 된 것은 잘못 학습된 데이터를 말한다
- 오류에 가중치를 부여해 다음 약한 학습기가 더 잘 분류할 수 있도록 한다
GBM
- AdaBoost와 유사하나 가중치 업데이트를 경사 하강법을 이용한다
- 일반적으로 랜덤 포레스트보다 예측 성능이 조금 뛰어나나 수행 시간이 오래걸리고 하이퍼 파라미터 튜닝을 신경써야 한다
- 과적합에도 강한 뛰어난 예측 성능을 가졌다
경사 하강법이란?
- 분류의 실제 결과값(레이블값)을 y로, 피처를 x1, x2...xn 그리고 피처에 기반한 예측 함수를 F(x)라고 하였을 때, 오류식 h(x) = y - F(x)를 최소화하는 방향성을 가지고 가중치를 업데이트하는 것을 경사 하강법이라고 한다
- 즉, y ~= F(x)가 되도록 가중치를 업데이트 하는 것을 말한다
GBM 클래스
- GradientBoostingClassifier() 이용
from sklearn.ensemble import GradientBoostingClassifier //모듈 임포트
GradientBoostingClassifier.fit(X_train, y_train) //학습
GradientBoostingClassifier.predict(X_test) //예측
GBM 하이퍼 파라미터
| loss -경사 하강법에서 사용할 비용 함수 지정 learning_rate -학습을 진행할 때마다 적용하는 학습률 -약한 학습기가 순차적으로 오류 값을 보정해 나가는데 적용하는 계수 -0~1 사이의 값을 지정할 수 있다 -default는 0.1 n_estimators -약한 학습기의 개수 -많을 수록 예측 성능이 좋아지나 수행 시간이 오래 걸린다 -default는 100 subsample -약한 학습기가 학습에 사용하는 데이터의 샘플링 비율 -default는 1이며 과적합이 염려될 경우 1보다 작은 값으로 설정 |
06. XGBoost(eXtra Gradient Boost)
XGBoost
- 트리 기반 앙상블 학습 중 하나이다
- 분류에 있어 뛰어난 예측 성능을 보인다
- GBM보다 빠르게 학습할 수 있다
- 자체 과적합 규제 기능이 있다
- 자체 교차 검증 기능이 있다
- 라이브러리가 C/C++로 작성되있다
- 수행 속도를 높이기 위한 조기 중단 (early stopping) 기능이 있다
조기 중단 기능
- n_estimators에 지정한 부스팅 반복 횟수에 도달하지 않더라도 예측 오류가 더 이상 개선되지 않으면 반복을 끝까지 수행하지 않고 중단해 수행 시간을 크게 줄인다
- 데이터 세트가 작은 경우엔 조기 중단을 사용할지 성능이 약간 저조할 수 있다
XGBoost 파이썬 래퍼 클래스
- xgboost
- 전용 데이터 객체인 DMatrix를 사용한다
import xgboost as xgb //모듈 임포트
xgb.DMatrix(data, label) //data는 피처 데이터 세트, label은 레이블 데이터 세트를 의미함- plot_importance() API를 통해 피처의 중요도를 막대그래프로 나타낼 수 있다
XGBoost 파이썬 래퍼 클래스의 주요 하이퍼 파라미터
| eta -학습률 objective -목적함수 early_stopping_rounds -조기 중단을 위한 최소 예측 반복 횟수 num_boost_round -GMB의 n_estimators min_child_weight -트리에서 추가적으로 가지를 나눌지 결정하기 위해 필요한 데이터들의 weight 총합 |
XGBoost 사이킷런 래퍼 클래스
- XGBClassifier / XGBRegressor
XGBoost 사이킷런 래퍼 클래스의 주요 하이퍼 파라미터
| learning_rate subsample n_estimators early_stopping_rounds -조기 종료를 위한 예측 반복 횟수 eval_metric -조기 중단을 위한 평가 지표 eval_set -성능 평가를 수행할 데이터 세트 |
from xgboost import XGBClassifier //모듈 임포트
XGBClassifier(n_estimators, learning_rate...)
eval_set = [(X_tr, y_tr), (X_val, y_val)] //앞의 튜플이 학습용 데이터, 뒤의 튜플이 검증용 데이터
XGBClassifier.fit(X_train, y_train, early_stopping_rounds, eval_metric, eval_set, verbose = True) //학습
XGBClassifier.predict() //예측07. LightGBM
LightGBM
- XGBoost보다 학습에 걸리는 시간과 메모리 사용량이 훨씬 적다
- XGBoost와 예측 성능에 별다른 차이가 없다
- 적은 데이터 세트에 적용할 경우 과적합이 발생하기 쉽다 (10,000건 이하)
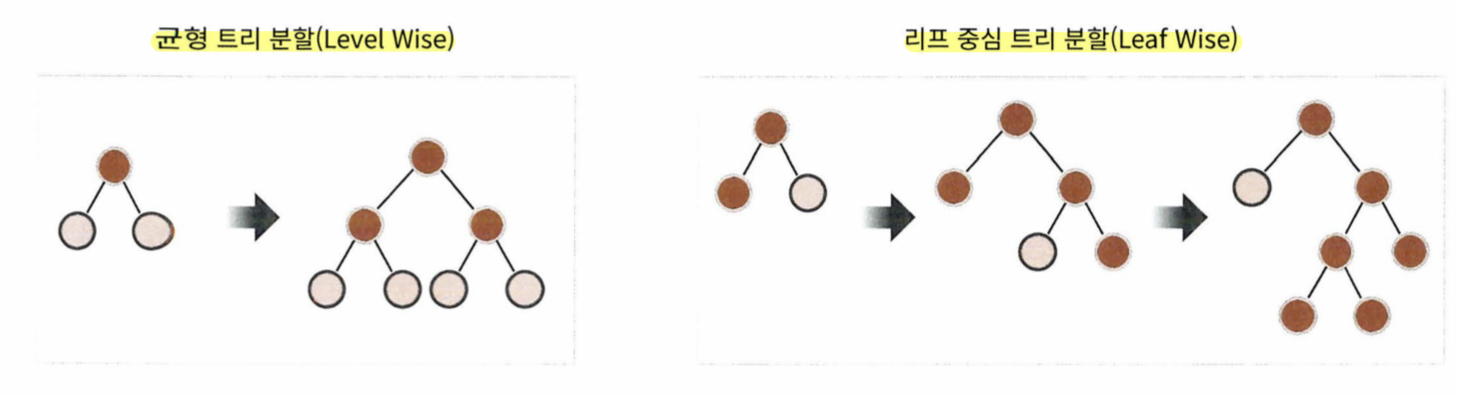
- 리프 중심 트리 분할 (Leaf Wise) 방식을 사용한다
리프 중심 트리 분할 (Leaf Wise)이란?
- 트리의 깊이를 효과적으로 줄이는 균형 트리 분할과 정반대이다
- 트리의 균형을 맞추기 않고 최대 손실 값 (max delta loss)을 가지는 리프 노드를 지속적으로 분할하면서 트리의 깊이깊어지고 비대칭적 트리가 생성된다
LightGBM 클래스
- LGBMClassifier / LGBMRegressor
LightGBM의 하이퍼 파라미터
- 리프 중심 트리 분할을 이용하기에 트리의 깊이가 깊어지므로 이에 따른 튜닝이 필요하다
| num_iterations (=n_estimators) -반복 수행하려는 트리의 개수를 지정 -너무 크게 지정하면 과적합 발생 -default는 100 leaning_rate -학습률 num_leaves -하나의 트리가 가질 수 있는 최대 리프 개수 -default는 31 min_child_samples -최종 결정 클래스인 리프 노드가 되기 위해서 최소한으로 필요한 레코드 수 -과적합 제어용 |
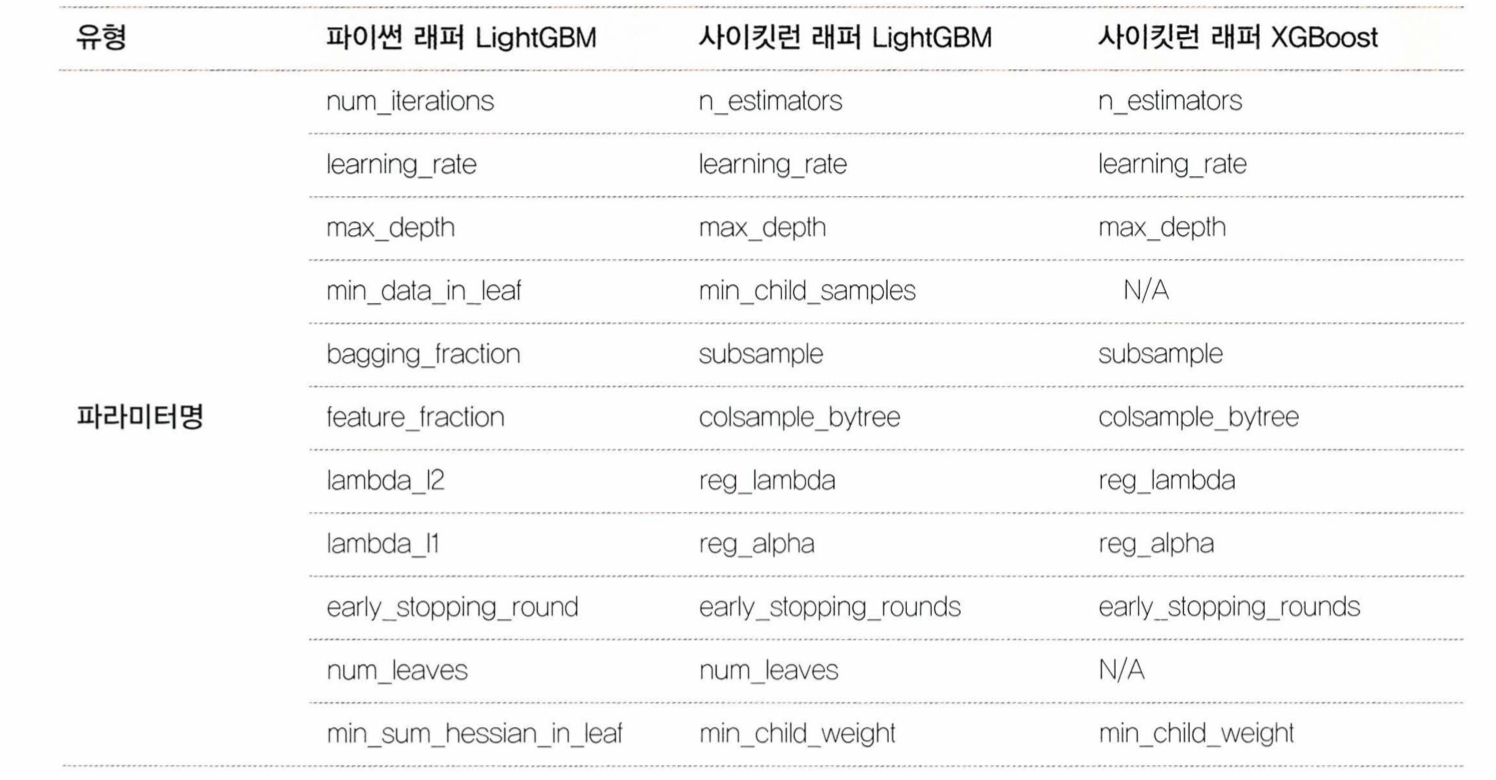
파이썬 래퍼 LightGBM과 사이킷런 래퍼 XGBoost, LightGBM의 하이퍼 파라미터 비교
from lightgbm import LGBMClassifier //모듈 임포트
LGBMClassifier(n_estimators, leaning_rate...)
LGBMClassifier.fit(X_tr, y_tr, early_stopping_rounds, eval_metric, eval_set, verbose = True) //학습
LGBMClassifier.predcit(X_test) //예측
피처 중요도 시각화
- plot_importance()
from lightgbm import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
//예시
fig, ax = plt.subplots(figsize = (10, 12))
plot_importance(LGBMClassifier, ax = ax)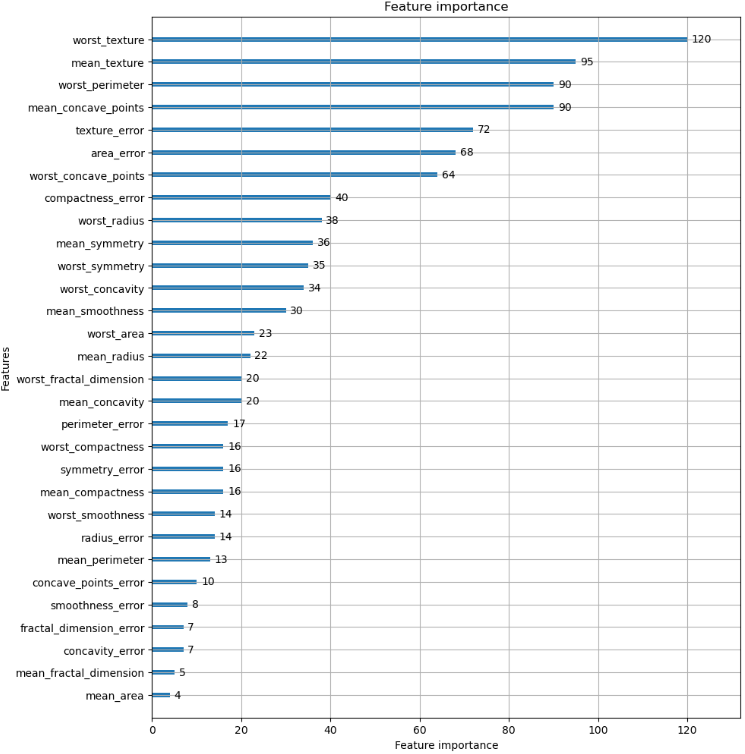
08. 베이지안 최적화 기반의 HyperOpt를 이용한 하이퍼 파라미터 튜닝
HyperOpt
- Grid Seach 방식보다 수행 시간이 줄여주는 하이퍼 파라미터 튜닝 방식
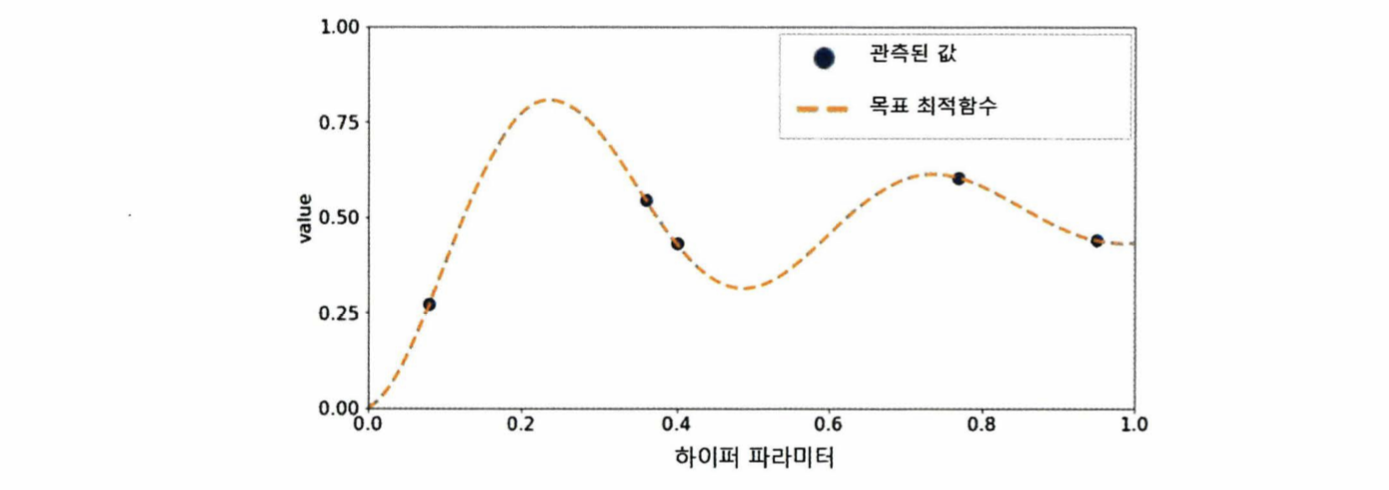
베이지안 최적화
- 목적 함수 식을 알 수 없는 상태에서 최대 또는 최소 함수 반환 값을 만드는 최적 입력값을 가능한 적은 시도를 통해 빠르고 효과적으로 찾아주는 방식
- 예를 들어 함수 f(x, y) = 2x - 3y의 반환값을 최대/최소로 하는 x, y을 찾는 것
- 단, 함수 식이 어떤지 알 수 없고 반환 값만 받을 수 있다
- 이름에서 알 수 있듯이 베이지안 확률에 기반을 두고 있는 최적화 기법
- 대체 모델과 획득 함수로 구성되어있다
최적화 방법

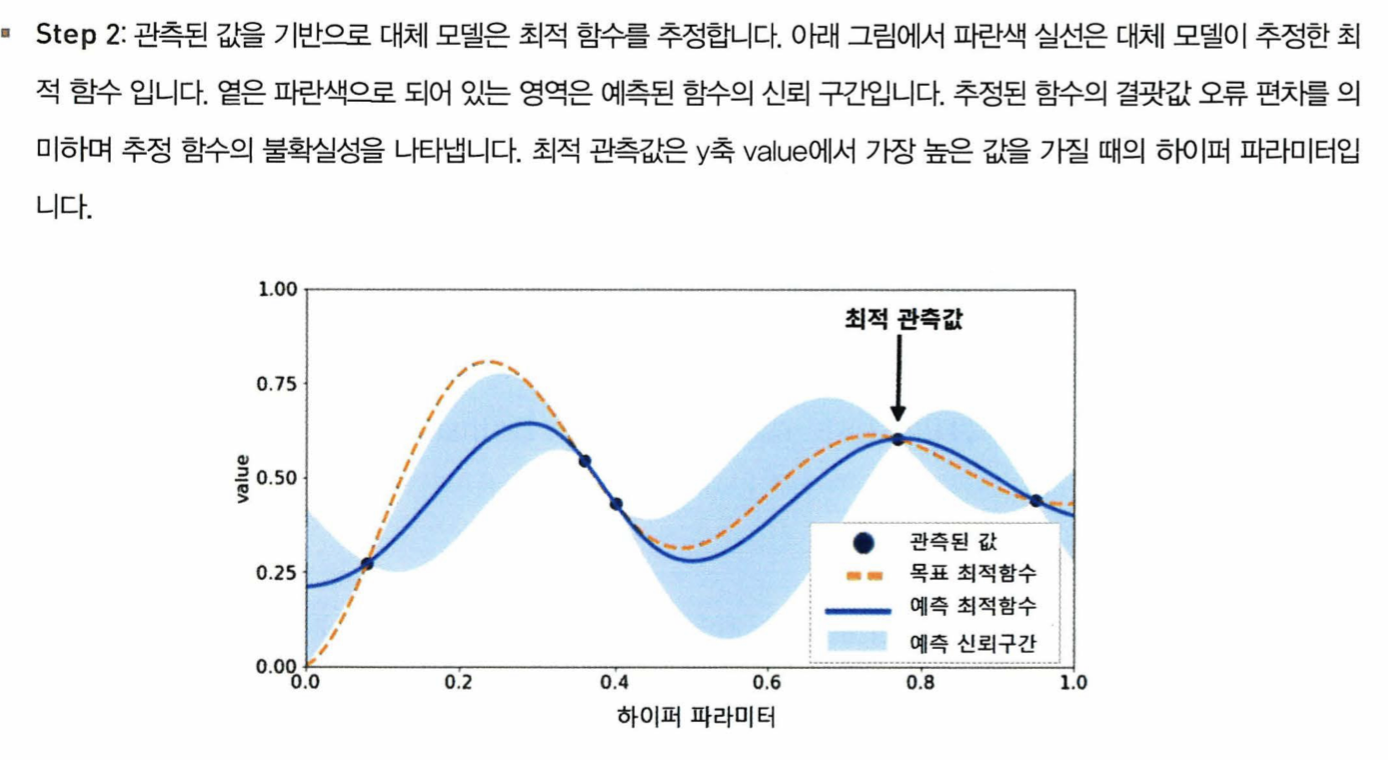
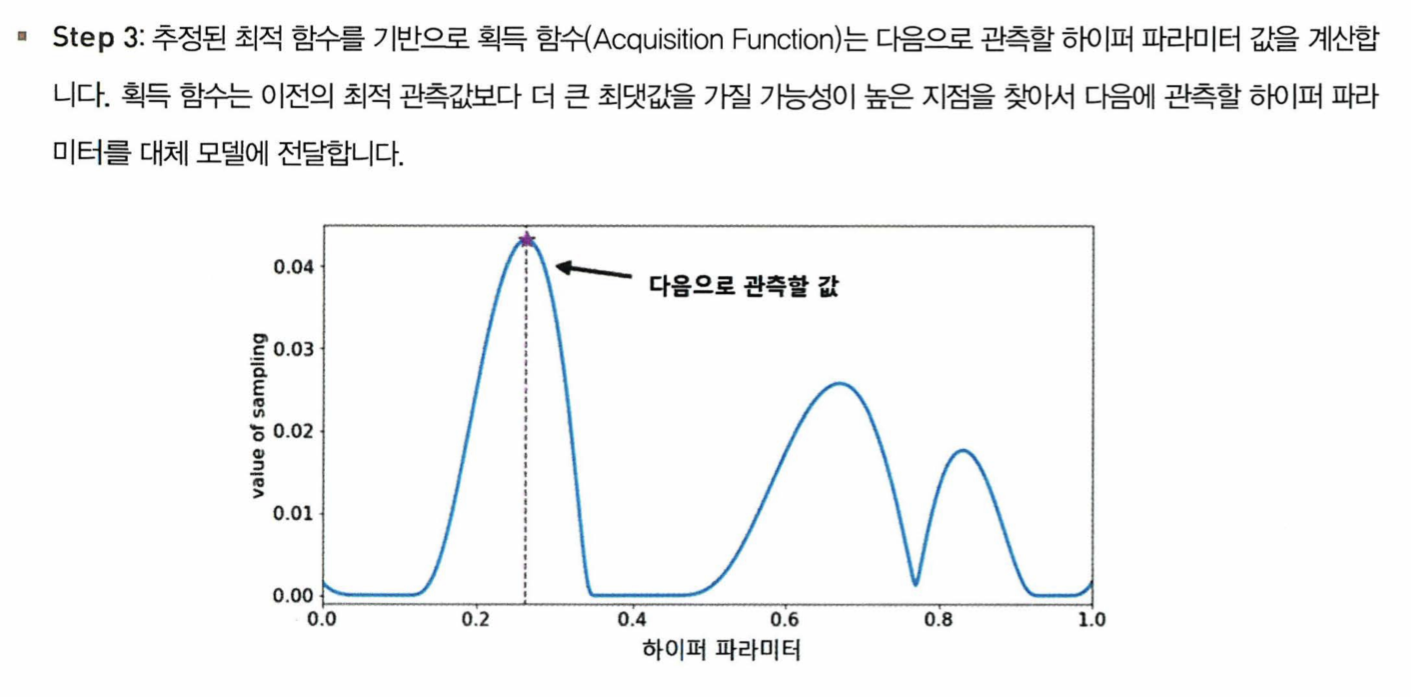
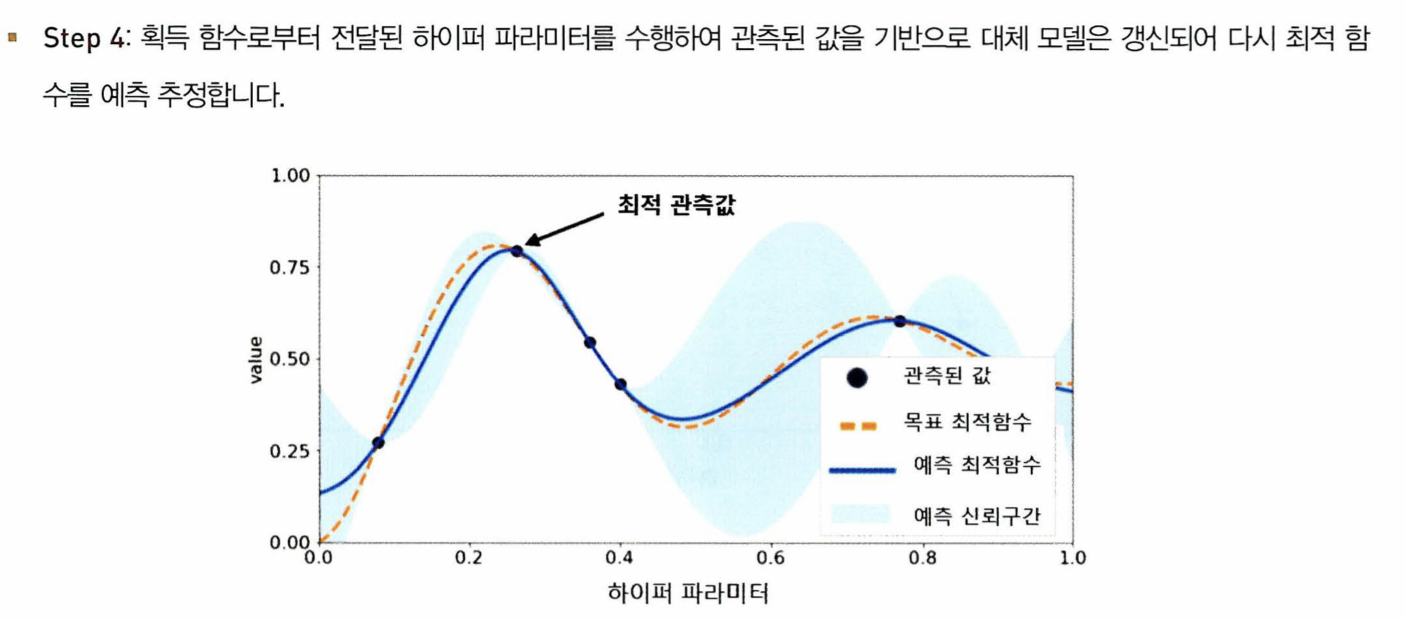
HyperOpt의 사용
- 다른 패키지와 다르게 목적 함수 반환 값이 최댓값이 아닌 최솟값을 가지는 최적 입력값을 유추한다
- hp 모듈을 이용해 입력 변수명과 입력값의 검색 공간을 파이썬 딕셔너리 형태로 설정한다
- 키(key) 값으로 입력 변수명, 밸류(value)값은 해당 입력 변수의 검색 공간이 주어진다
//입력값 검색 공간 지정
from hyperopt import hp
//예시
// -10 ~ 10까지 1간격을 가지는 입력 변수 x와 -15 ~ 15까지 1간격으로 입력 변수 y 설정
search_space = {'x' : hp.quniform('x', -10, 10, 1), 'y': hp.quniform('y', -15, 15, 1)}
입력값의 검색 공간을 제공하는 함수들

//목적 함수 생성
//반드시 변숫값과 검색 공간을 가지는 딕셔너리를 인자로 받고 특정 값을 반환하는 구조여야 한다
from hyperopt import STATUS_OK
//예시
// 목적 함수를 생성. 변숫값과 변수 검색 공간을 가지는 딕셔너리를 인자로 받고, 특정 값을 반환
def objective_func(search_space):
x = search_space['x']
y = search_space['y']
retval = x**2 - 20*y
return retval
- 입력값의 검색 공간과 목적 함수를 설정 했으면 목적 함수의 반환값이 최소가 될 수 있는 최적의 입력값을 베이지안 최적화 기법에 기반해서 찾아야 한다
- fmin() 함수를 통해 이를 찾을 수 있다
- fmin() 함수의 주요 인자들

- fmin() 사용
from hyperopt import fmin, tpe, Trials
# 입력 결과값을 저장한 Trials 객체값 생성
trial_val = Trials()
# 목적 함수의 최솟값을 반환하는 최적 입력 변숫값을 20번의 입력값 시도 (max_evals = 20)로 찾아냄
best_02 = fmin(fn = objective_func, space = search_space, algo = tpe.suggest, max_evals = 20, trials = trial_val, rstate = np.random.default_rng(seed = 0))
print('best:', best_02)
- HyperOpt의 목적 함수는 최솟값을 반환할 수 있도록 최적화하기 때문에 정확도와 같이 값이 클수록 좋은 성능 지표일 경우 -1을 곱한 뒤 반환해야 한다
- XGBoostClassifier의 정수형 하이퍼 파라미터값으로 설정할 때는 정수형으로 형변환을 해야 한다
09 분류 실습 - 캐글 산탄데르 고객 만족 예측
- ROC-AUC를 이용해 성능 평가를 하므로 목적 함수를 만들 때 반환값에 -1을 곱해줘야 한다
10 분류 실습 - 캐글 신용카드 사기 검출
- 불균형한 데이터를 학습시킬 때는 (이상 레이블을 가지는 데이터 건수가 매우 적을 때) 오버 샘플링과 언더 샘플링이 필요하다

- 오버 샘플링의 대표적인 방식으로 SMOTE(Synthetic Minority Over-sampling Technique)이 있다
- fit_resample() 메소드 이용해 데이터를 증식한다
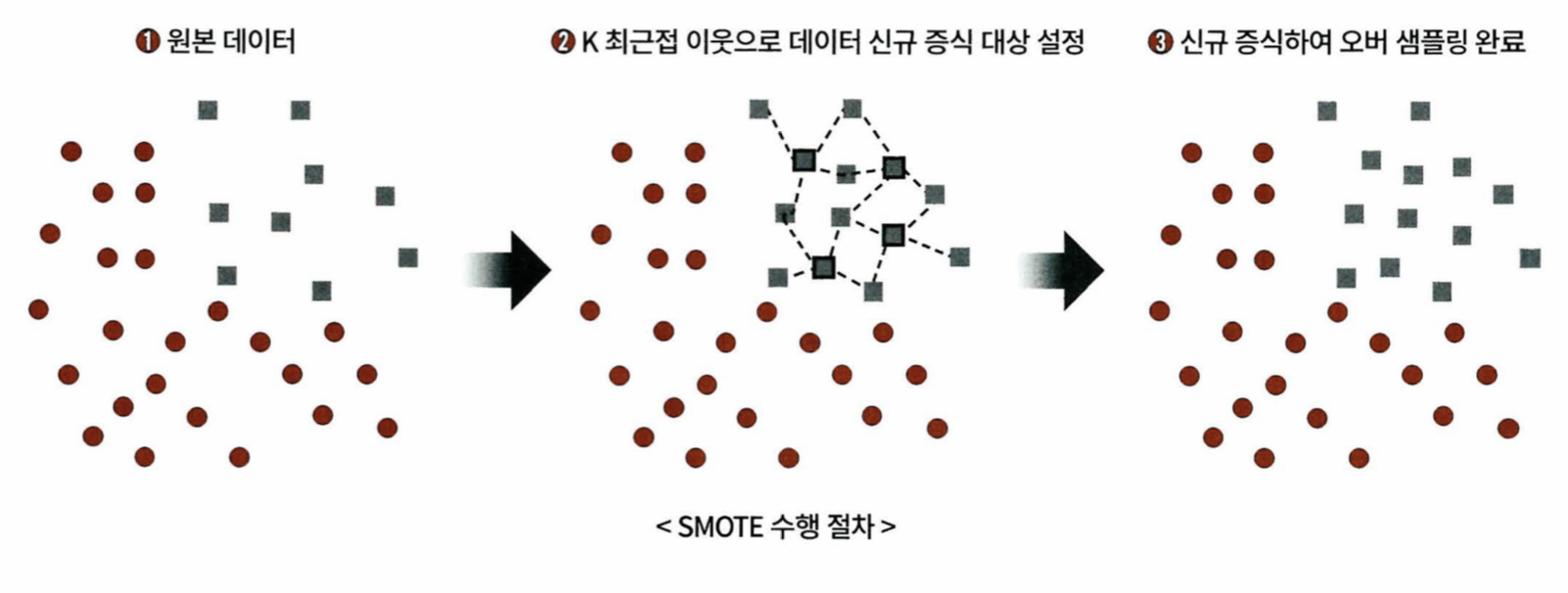
from imblearn.over_sampling import SMOTE //모듈 임포트
SMOTE.fit_resample(X_train, y_train) //데이터 증식- 데이터 분포도가 심하게 왜곡되있을 때 로그 변환을 이용하기도 한다
- 원래 값을 log값으로 바꿔 상대적으로 작은 값으로 변환해준다
- 레이블이 극도로 불균일한 데이터 세트에서 로지스틱 회귀는 데이터 변환 시 약간은 불안정한 성능을 보여준다
이상치 데이터 제거
- IQR (Inter Quantile Range) 를 이용한다
IQR이란?
- 사분위 값의 편차를 이용하는 기법
- 전체 데이터를 값이 높은 순으로 정렬하고 1/4씩 구간을 나눈다
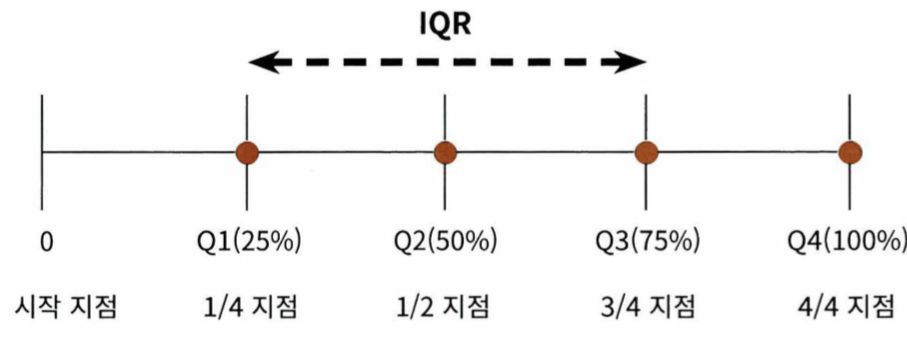
- 3/4 분위수 (Q3)에 IQR*1.5를 더해서 일반적인 데이터가 가질 수 있는 최댓값으로 가정
- 1/4 분위수 (Q1)에 IQR*1.5를 빼서 일반적인 데이터가 가질 수 있는 최솟값으로 가정

11 스태킹 앙상블
- 개별 알고리즘의 예측 결과 데이터 세트를 최종적인 메타 데이터 세트로 만들어 별도의 ML 알고리즘으로 최종학습을 수행하는 것을 말한다
- 개별적인 기반 모델과 이 개별 기반 모델의 예측 데이터를 학습 데이터로 만들어서 학습하는 최종 메타 모델이 필요하다
- 스태킹을 사용할 땐 많은 개별 모델이 필요하며 현실에서 자주 사용하지는 않는다
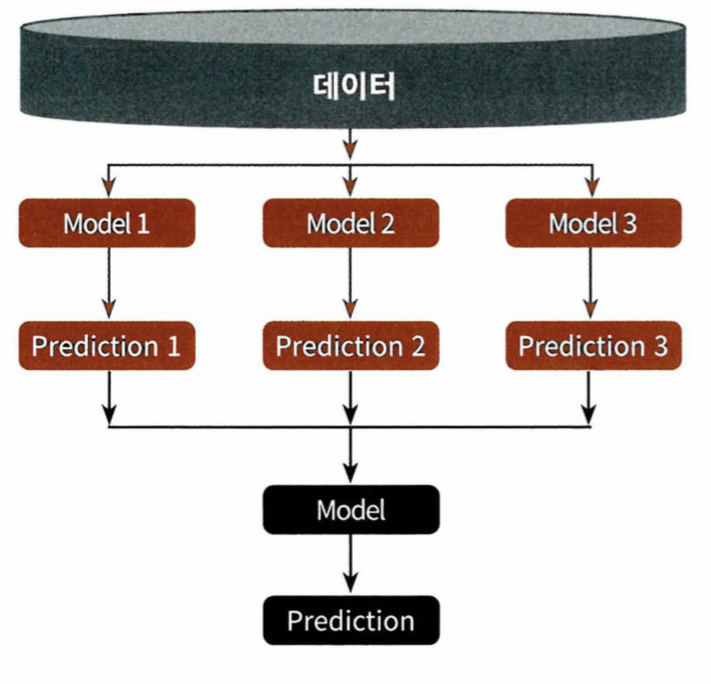
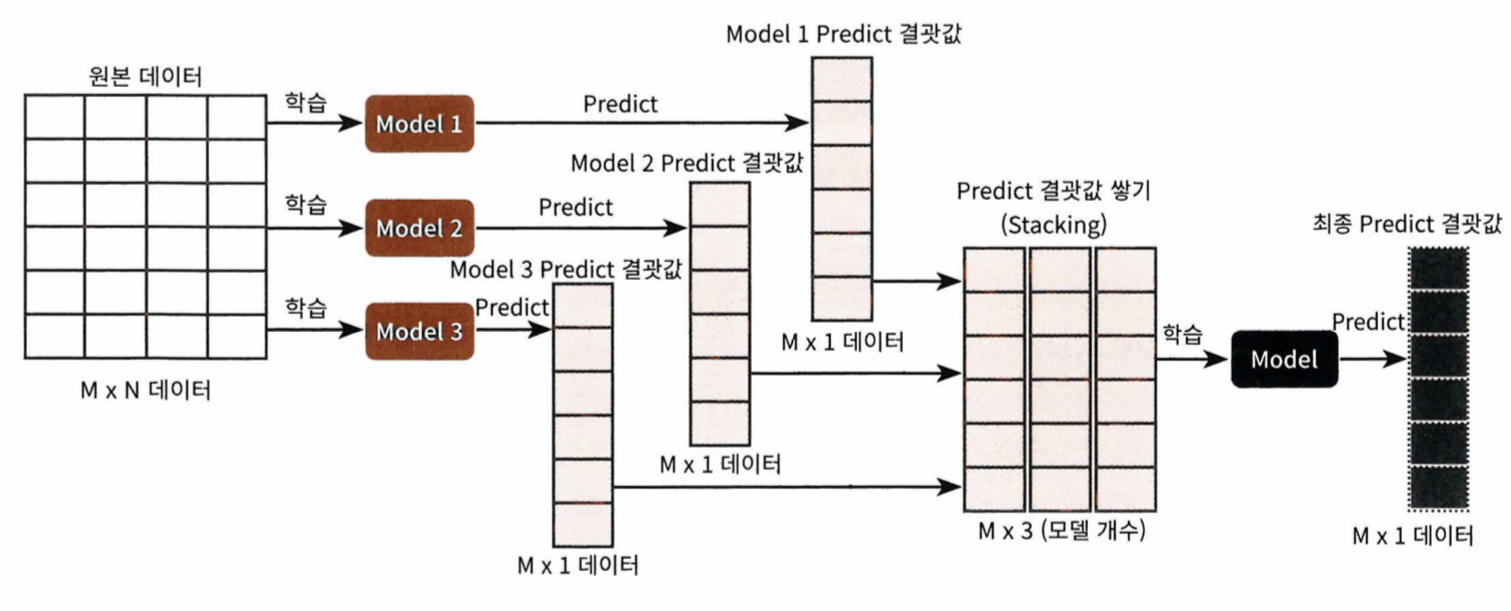
1. 개별 모델들 학습
2. pred = np.array([개별 모델들 예측])
3. pred = np.transpose(pred) // 행열을 바꿔서 스태킹
CV 세트 기반의 스태킹
- 개별 모델들이 각각 교차 검증으로 메타모델을 위한 학습용 스태킹 데이터와 예측을 위한 테스트용 스태킹 데이터를 만든다
- 만들어진 데이터를 기반으로 메타 모델이 학습과 예측을 수행한다
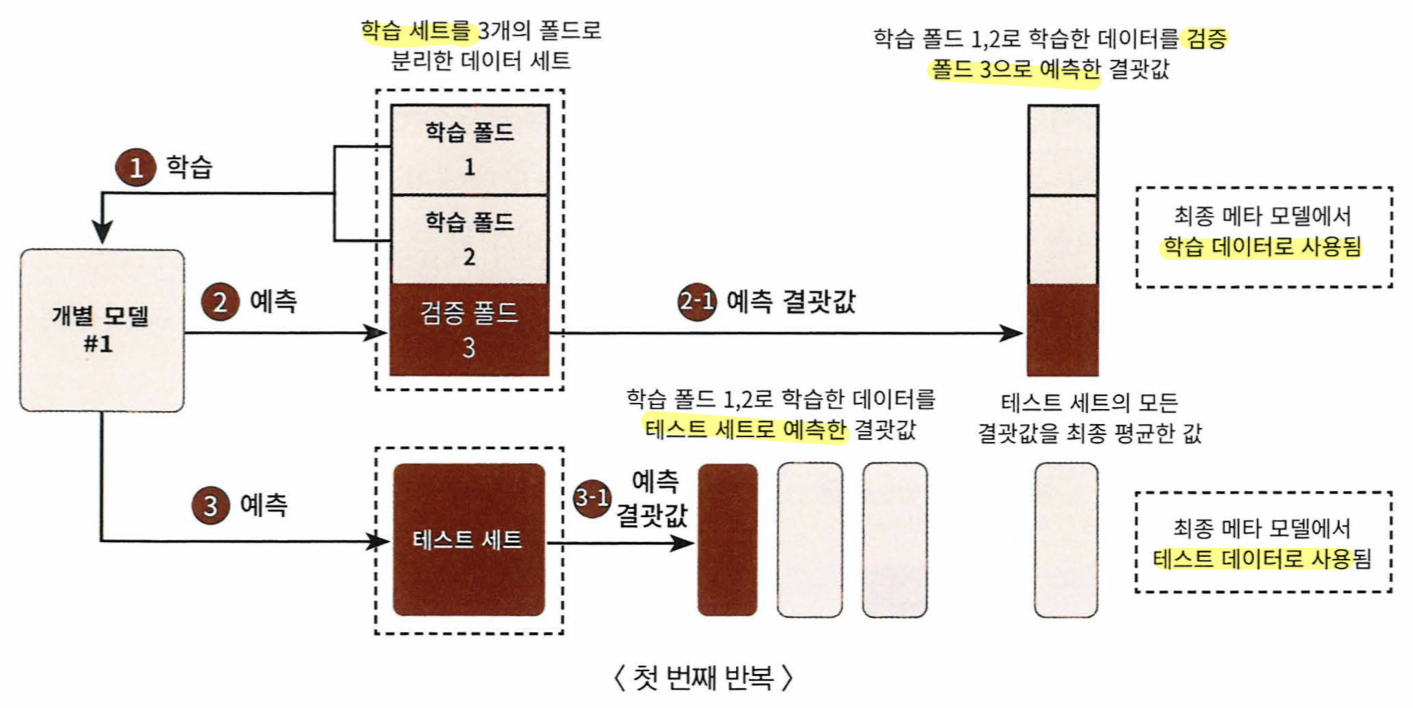
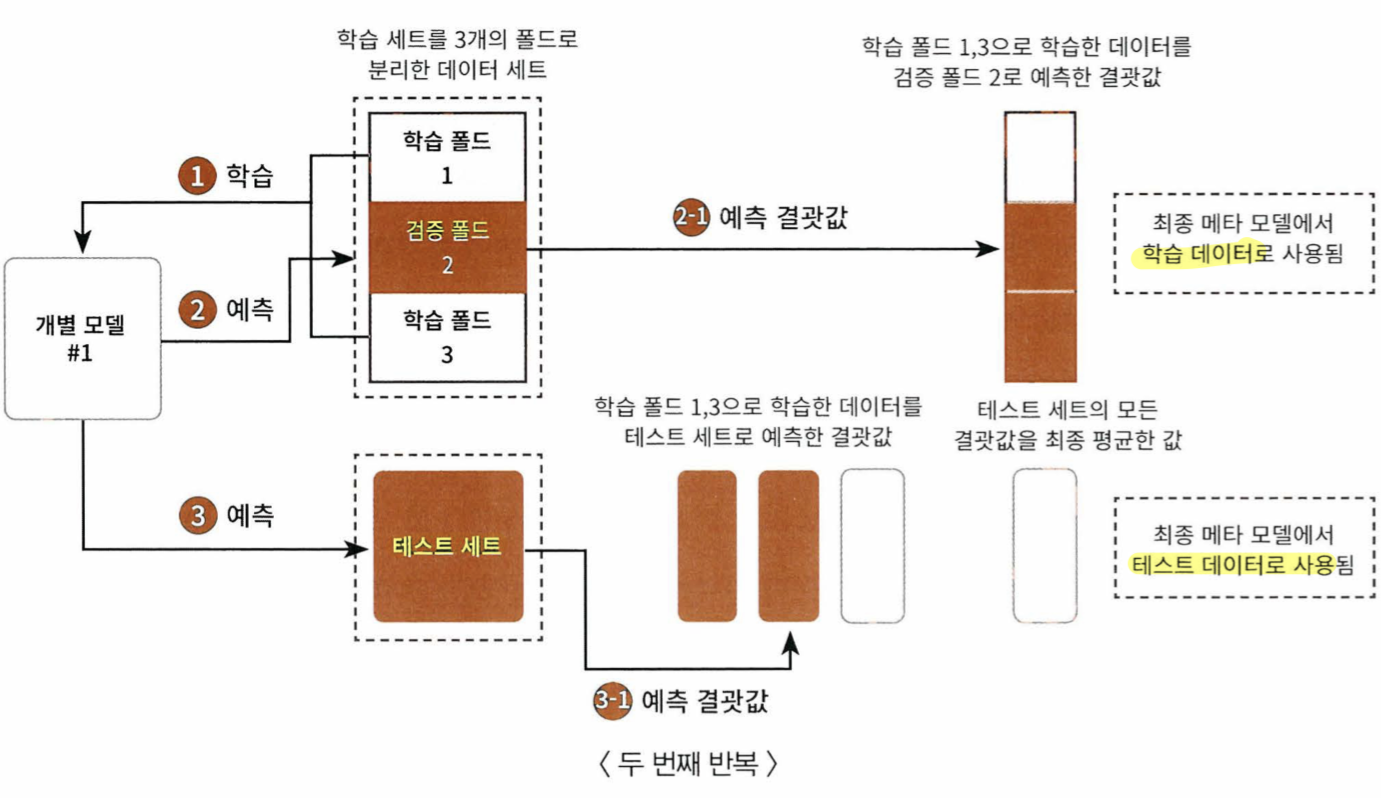
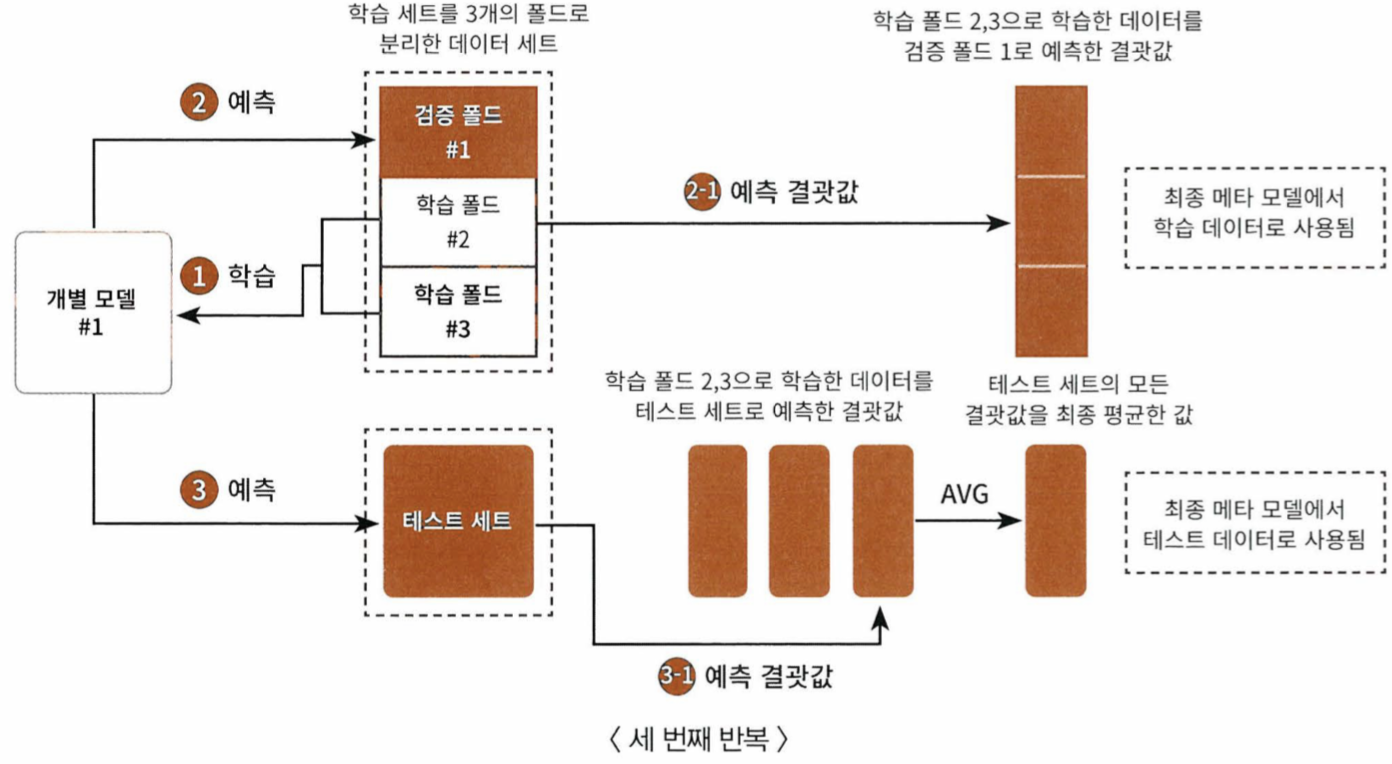

- 스텝1 에서 생성된 각 모델 별의 학습 데이터와 테스트 데이터는 넘파이의 concatenate()를 이용해 합친다
'Study > 파이썬 머신러닝' 카테고리의 다른 글
| 파이썬 머신러닝 스터디 6주차 (ch06 차원 축소) (0) | 2024.05.08 |
|---|---|
| 파이썬 머신러닝 스터디 5주차 (ch05 회귀) (0) | 2024.05.04 |
| 파이썬 머신러닝 스터디 3주차 (ch04-1 분류) (2) | 2024.04.04 |
| 파이썬 머신러닝 스터디 2주차 (ch03 평가) (2) | 2024.03.28 |
| 파이썬 머신러닝 스터디 1주차 (ch01 넘파이와 판다스) (0) | 2024.03.23 |



