
Notice
Recent Posts
Recent Comments
Link
Hello It's good to be back ^_^
파이썬 머신러닝 스터디 2주차 (ch03 평가) 본문
교재: 파이썬 머신러닝 완벽 가이드
공부한 페이지 : 85p~172p
실습한 내용: https://github.com/HongYeonLee/Pylot_MachineLearningStudy
GitHub - HongYeonLee/Pylot_MachineLearningStudy
Contribute to HongYeonLee/Pylot_MachineLearningStudy development by creating an account on GitHub.
github.com
목차
01. 정확도 (Accuracy)
02. 오차행렬 (Confusion Matrix)
03. 정밀도와 재현율 (Precision and Recall)
- 정밀도/재현율 트레이드오프
- 정밀도와 재현율의 맹점
04. F1 스코어
05. ROC 곡선과 AUC
머신러닝의 순서
데이터 가공/변환 → 모델 학습/예측 → 평가(Evaluation)
- 모델이 회귀모델일 경우 → 예측값의 오차를 기반으로 모델 평가
- 모델이 분류모델일 경우
- 정확도(Accuracy)
- 오차행렬(Confusion Matrix)
- 정밀도(Precision)
- 재현율(Recall)
- F1 스코어
- ROC AUC 기반으로 모델 평가
- 분류는 이진 분류와 멀티 분류로 나눌 수 있음
- 분류 모델을 평가하는데 사용되는 성능 평가 지표들은 이진 분류에서 특히 많이 사용함
- 이진 분류 - 긍정/부정, True/False, 0/1 처럼 2개의 결정 클래스 값을 가지는 것
- 멀티 분류 - 여러개의 결정 클래스 값을 가지는 것
01. 정확도 (Accuracy)
- 실제 데이터에서 예측데이터가 얼마나 같은지 판단하는 지표
- 이진 분류의 경우 불균형한 레이블 값 분포에서 머신러닝 모델의 성능이 왜곡될 수 있기 때문에 정확도만을 사용하진 않음
- 예시 - 타이타닉 생존자 데이터에서 여자면 모두 생존, 남자면 모두 사망으로 예측을 해도 정확도가 78%가 나옴

02. 오차 행렬 (Confusion Matrix)
- 분류 모델이 예측이 수행하면서 어떠한 유형의 예측 오류를 발생하는지 보여주는 지표
- 4분면을 기준으로 왼쪽, 오른쪽은 '예측' 클래스의 값을 기준으로 Negative(왼) / Positive(오)
- 4분면을 기준으로 위, 아래는 '실제' 클래스의 값을 기준으로 Negative(위) / Positive(아래)
| TN - 진짜 음성 (실제로 음성이고 예측도 음성으로 함) | FP - 가짜 양성 (실제로 음성이나 예측은 양성으로 함) |
| FN - 가짜 음성 (실제로 양성이나 예측은 음성으로 함) | TP - 진짜 양성 (실제로 양성이고 예측도 양성으로 함) |
from sklearn.metrics import confusion_matrix
confusion_matrix( ) //파라미터로 테스터 데이터와 예측 값을 넣어주면 됨
//사용 예시
confusion_matrix(y_test, fakepred)
//output (ndarray형태로 리턴)
array([[405, 0],
[45, 0]], dtype = int 45)
| TP (진짜 양성) 405개 | FP (가짜 양성) 0개 |
| FN (가짜 음성) 45개 | TP (진짜 양성) 0개 |
- TP, TN, FP, FN을 조합해 정확도, 정밀도, 재현율의 값을 구할 수 있다
정확도 = (TP + TN) / (TP + TN + FP + FN)
- Positive 건수가 굉장히 적은 데이터 세트 (암 진단, 금융 거래 사기 등) 에서는 Negative로 예측을 하는 성향이 강해짐
- TN (진짜 음성)이 매우 증가하고 TP (진짜 양성), FN (가짜 음성), FP (가짜 양성)은 전부 매우 감소함
- 따라서 정확도만으로는 불균형한 데이터세트에서 모델 평가를 내리기 어렵다
03 정밀도와 재현율 (Precision and Recall)
- Positive 데이터 세트의 예측 성능에 더 용이함
- 정밀도
정밀도 = TP / (FP + TP) = 진짜 양성 / (가짜 양성 + 진짜 양성)
- 예측을 positive로 한 대상 중에 예측과 실제 값이 positive로 일치한 데이터의 비율
- Positive 예측 성능을 더욱 정밀하기 측정하기 위해 평가 지표로 양성 예측도라고 부르기도 함
- 실제 negative 음성 데이터를 positive로 잘못 판단하면 큰 일이 날 때 사용함
- FP (가짜 양성)를 낮추는데 초점을 맞춤
- 즉 negative로 판단 능력이 중요한 상황에서 모델을 평가하는 지표로 사용함
- 예) 스팸메일 여부
from sklearn.metrics import precision_score
pricision_score( ) //파라미터로 테스터 데이터와 예측 값을 넣어주면 됨
2. 재현율
재현율 = TP / (FN + TP) = 진짜 양성 / (가짜 음성 + 진짜 양성)
- 실제 값이 positive인 대상 중에 예측과 실제 값이 positive로 일치한 데이터의 비율
- 민감도 (Sensitivity) 또는 TPR (True Positive Rate)라고 부르기도 함
- 실제 positive 양성 데이터를 negative로 잘못 판단하면 큰 일이 날 때 사용함
- FN (가짜 음성)을 낮추는데 초점을 맞춤
- 즉 positive로 판단하는 능력이 중요한 상황에서 모델을 평가하는 지표로 사용함
- 예) 암 판단 모델, 금융 사기 적발 모델
from sklean.metrics import recall_score
recall_score( ) //파라미터로 테스터 데이터와 예측 값을 넣어주면 됨
- 정밀도와 재현율은 서로 보완적인 관계이므로 둘다 높은 수치인 것이 좋다
3. 정밀도/재현율 트레이드오프
- 임곗값보다 크면 positive, 작으면 negative로 결정한다
- 분류의 결정 임곗값(Threshold)를 조정해 정밀도 또는 재현율을 높일 수 있다
- 그러나 어느 한쪽을 높이면 다른 한쪽은 떨어지기 쉽다
- 이를 정밀도/재현율 트레이드오프(Trade-off)라고 부른다
- 개별 데이터별로 예측 확률을 반환하는 메서드 predict_proba( )
- 파라미터로 테스트 피처 데이터 세트를 입력하면 테스트 피처 레코드의 개별 클래스 예측 확률을 리턴
- predict_proba( )가 반환하는 ndarray의 첫번째 칼럼이 클래스 값 0에 대한 예측 확률
- predict_proba( )가 반환하는 ndarray의 두번째 칼럼이 클래스 값 1에 대한 예측 확률

두개의 class 중에서 더 큰 확률을 클래스 값으로 예측
[[0.44935228 0.55064772 1. ]
[0.86335513 0.13664487 0. ]
[0.86429645 0.13570355 0. ]]
- Binarizer 객체를 이용해 threshold 값을 조정할 수 있다
from sklearn.preprocessing import Binarizer
X = [[ 1, -1, 2],
[ 2, 0, 0],
[ 0, 1.1, 1.2]]
# threshold 기준값보다 같거나 작으면 0을, 크면 1을 반환
binarizer = Binarizer(threshold = 1.1)
print(binarizer.fit_transform(X))
//output
[[0. 0. 1.]
[1. 0. 0.]
[0. 0. 1]]
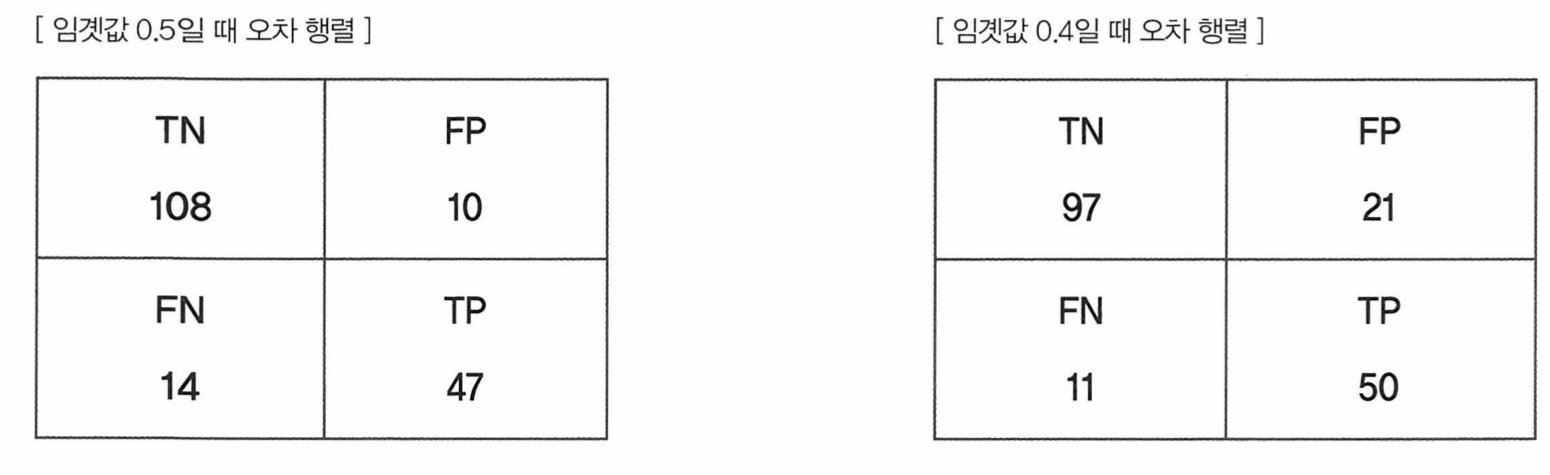
- 임곗값이 작아졌을 때 -> TN (진짜 음성) 감소, FP (가짜 양성) 증가, FN (가짜 음성) 감소, TP (진짜 양성) 증가
- 임곗값이 작아짐 -> positive 예측을 더 많이 함 -> 진짜 양성이 증가하고 가짜 양성도 증가함, 진짜 음성과 가짜 음성은 감소함 -> 재현율 증가 TP / (FN + TP), 정밀도 감소 TP / (FP + TP)
- precision_recall_curve ( ) 를 이용해 임곗값별 정밀도와 재현율을 구할 수 있다

- 임곗값에 따른 정밀도와 재현율의 변화를 곡선 형태의 그래프로 시각화할 수 있다
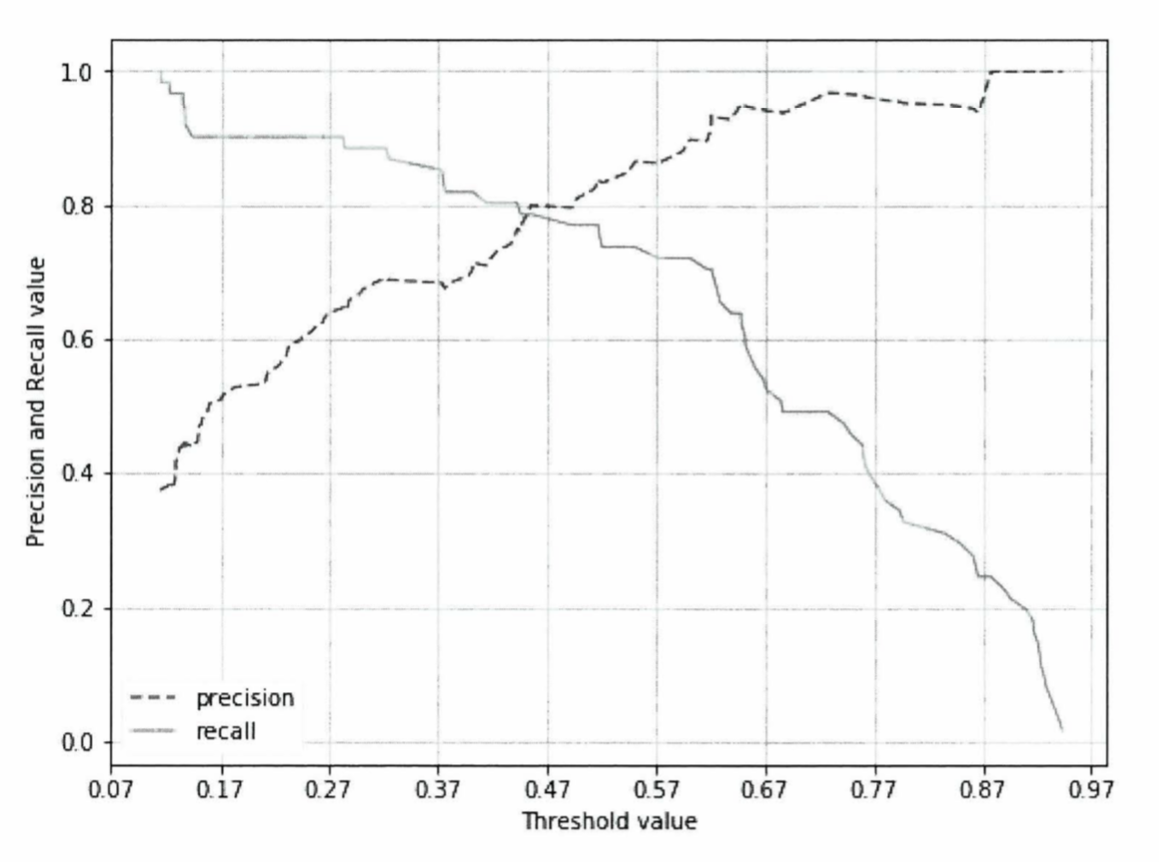
- 임곗값이 증가할 수록 정밀도(점선)는 증가하고 재현율은 감소하는 것을 볼 수 있다
- 임곗값 증가 -> 양성 예측이 적어짐 -> 음성 예측이 증가함 -> TN, FN 증가 -> 정밀도 증가
- 임곗값이 감소할 수록 재현율 (실선)은 증가하고 정밀도는 감소하는 것을 볼 수 있다
- 임곗값 감소 -> 양성 예측이 많아짐 -> 음성 예측이 감소함 -> TP, FP 증가 -> 재현율 증가
- 정밀도와 재현율이 비슷한 수치를 갖는 임곗값을 선택하는 것이 좋다
정밀도가 100%가 되는 방법
- 확실한 기준이 되는 경우만 positive로 예측하고 나머지는 모두 negative로 예측
- TP / ( FP + TP )에서 FP가 사라져서 1이 됨
재현율이 100%가 되는 방법
- 모든 데이터를 positive로 예측
- TP / ( FN + TP )에서 FN이 사라져서 1이 됨
04 F1 스코어
- 정밀도와 재현율을 결합한 지표로, 두 수치가 한 쪽으로 치우치지 않을 때 상대적으로 높은 값을 가짐
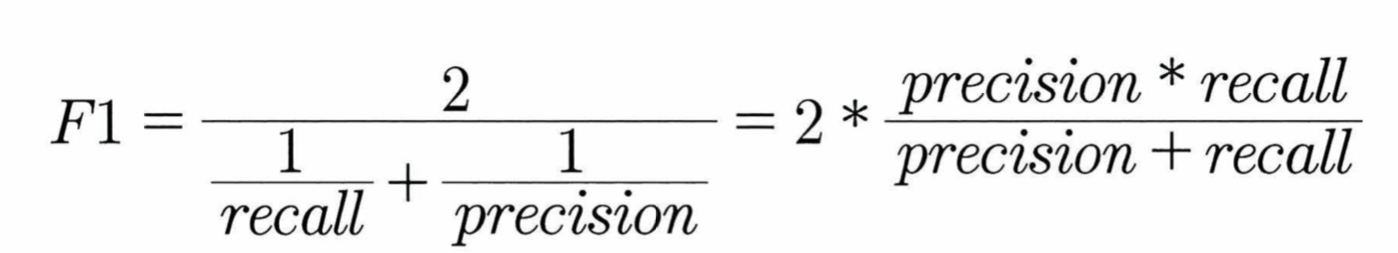
- f1_score( )를 이용해 F1 스코어를 구할 수 있다
from sklearn.metrics import f1_score
f1_score( ) //파라미터로 테스터 데이터와 예측값을 넣으면 된다
05 ROC 곡선과 AUC
- ROC 곡선
- FPR(False Positive Rate)이 변할 때 TPR(True Positive Rate)이 어떻게 변하는지 나타내는 곡선
FPR = FP / ( FP + TN )
TPR = TP / ( FN + TN )
TPR (민감도) = 실제 양성이 정확히 예측되는 수준 (= 재현율)
TNR = TN / ( FP + TN )
TNR (특이성) = 실제 음성이 정확히 예측되는 수준
- TPR (= 재현율, 민감도) <-> TNR (True Negative Rate) (= 특이성)
- FPR과 TNR의 분모가 똑같으므로 FPR = 1 - TNR = 1 - 특이성으로 표현할 수 있다
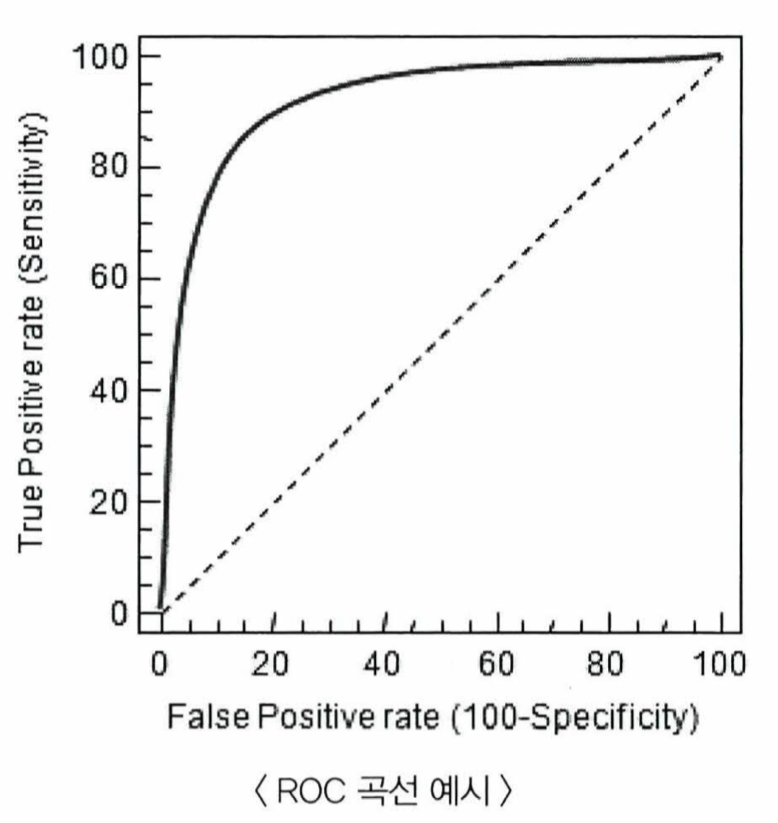
FPR = FP / ( FP + TN )
- 대각선 점선은 ROC 곡선의 최저 값으로 예측을 했을 때 가짜 양성과 진짜 양성의 비율이 50% 나오는 수준을 의미함
- FPR을 0으로 만들기 -> 임곗값을 1로 지정하기 -> 전부 negative로 예측 함 -> FP가 0이 됨 -> FPR = 0
- FPR을 1로 만들기 -> 임곗값을 0으로 지정하기 -> 전부 positive로 예측 함 -> TN이 0이 됨 -> FPR = 1
- roc_curve( )를 이용해 ROC 곡선을 구할 수 있다

from sklearn.metrics import roc_curcve
roc_curve( ) //파라미터로 테스터 데이터 값, predict_proba()의 리턴값을 넣으면 된다
2. AUC
- Area Under Curve의 약자
- AUC가 1에 가까울 수록 좋은 수치
- AUC가 커지려면 FPR이 작은 상태에서 큰 TPR을 얻으면 됨
+ 발표 시간도 가졌습니다! :)

'Study > 파이썬 머신러닝' 카테고리의 다른 글
| 파이썬 머신러닝 스터디 6주차 (ch06 차원 축소) (0) | 2024.05.08 |
|---|---|
| 파이썬 머신러닝 스터디 5주차 (ch05 회귀) (0) | 2024.05.04 |
| 파이썬 머신러닝 스터디 4주차 (ch04-2 분류) (0) | 2024.04.11 |
| 파이썬 머신러닝 스터디 3주차 (ch04-1 분류) (2) | 2024.04.04 |
| 파이썬 머신러닝 스터디 1주차 (ch01 넘파이와 판다스) (0) | 2024.03.23 |
'Study/파이썬 머신러닝' Related Articles
more



