
Hello It's good to be back ^_^
파이썬 머신러닝 스터디 3주차 (ch04-1 분류) 본문
교재: 파이썬 머신러닝 완벽 가이드
공부한 페이지: 181p ~ 221p
실습한 내용: https://github.com/HongYeonLee/Pylot_MachineLearningStudy
GitHub - HongYeonLee/Pylot_MachineLearningStudy
Contribute to HongYeonLee/Pylot_MachineLearningStudy development by creating an account on GitHub.
github.com
목차
01. 분류(Classification)의 개요
02. 결정 트리(Decision Tree)
03. 앙상블 학습(Ensemble Learning)
- 정밀도/재현율 트레이드오프
- 정밀도와 재현율의 맹점
04. 랜덤 포레스트
01 분류의 개요
- 분류는 대표적인 지도학습 유형
- 데이터의 피처와 레이블(=결정 값, 클래스 값)을 학습해 미지의 레이블을 예측하는 방법 중 하나
- 피처의 예시 ex) 사람의 키, 몸무게, 골격근량 등
- 레이블의 예시 ex) 여자, 남자
분류에 사용되는 다양한 알고리즘들
- 베이즈 통계
- 로지스틱 회귀
- 결정 트리
- 서포트 벡터 머신
- 최소 근접 알고리즘
- 신경망
- 앙상블
02 결정 트리
- 머신러닝 알고리즘 중 가장 직관적으로 이해하기 쉬운 알고리즘
- if / else를 이용해 데이터를 트리(tree) 모양으로 분류함

| 루트 노드 -가장 처음으로 데이터를 분류하는 노드 규칙 노드 -데이터를 분류하는 규칙이 되는 노드 리프 노드 -규칙에 의해 분류되어 더이상 분류될 수 없는 결정된 레이블 값 (= 결정값, 분류값, 클래스값) 브랜치/서브트리 -규칙 노드에 의해 분류되어 새롭게 생겨나는 트리 |
트리의 깊이 (=길이)가 깊어질 수록 결정 트리의 예측 성능이 저하되니 주의한다
데이터를 분류하는 규칙은 '균일도'에 기반한다
균일도란?
- 같은 데이터가 얼마나 많은지를 나타내는 지표이다.
- 규칙 노드의 규칙은 정보 균일도가 높은 데이터 세트를 분류할 수 있게 만들어진다
균일도를 측정하는 방법
- 정보이득지수
- 지니 계수
정보이득지수
- 엔트로피 기반
- 1 - 엔트로피 지수
- 높을 수록 균일도가 높음
지니 계수
- 경제학에서 사용하는 불평등 지수
- 낮을 수록 균일도가 높음
결정 트리 클래스
- DecisionTreeClassifier 지니 계수를 기반으로 데이터를 분류함
from sklearn.tree import DecisionTreeClassifier
DecisionTreeClassifier()
//사용예시
dt_clf = DecisionTreeClassifier.fit(X_train, y_train)
- DecisionTreeClassifier()의 파라미터
| min_smaples_split (노드를 분할하기 위한 최소한의 샘플 데이터 수, 디폴트는 2) min_samples_leaf (분할될 경우 왼쪽과 오른쪽 노드가 가져야할 최소한의 샘플 데이터 수) max_features (분류할 때 고려할 최대 피처 수, 디폴트는 None) max_depth (트리의 최대 깊이, 디폴트는 None) max_leaf_mondes (말단 노드의 최대 개수) |
결정 트리를 시각화해주는 패키지 Graphviz
- export_graphviz() - Graphviz가 그래프 형태로 시각화 할 수 있는 출력 파일을 생성해주는 함수
from sklearn.tree import export_graphviz
export_graphviz() //파라미터로 학습이 된 Estimator, 피처의 이름 리스트, 레이블 이름 리스트
//사용예시
export_graphviz(dt_clf, out_file = "tree.dot", class_names = iris_data.target_names, feature_names = iris_data.feature_names, impurity = True, filled = True)
// tree.dot 파일이 생성됨import graphviz
with open("생성된 파일명") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)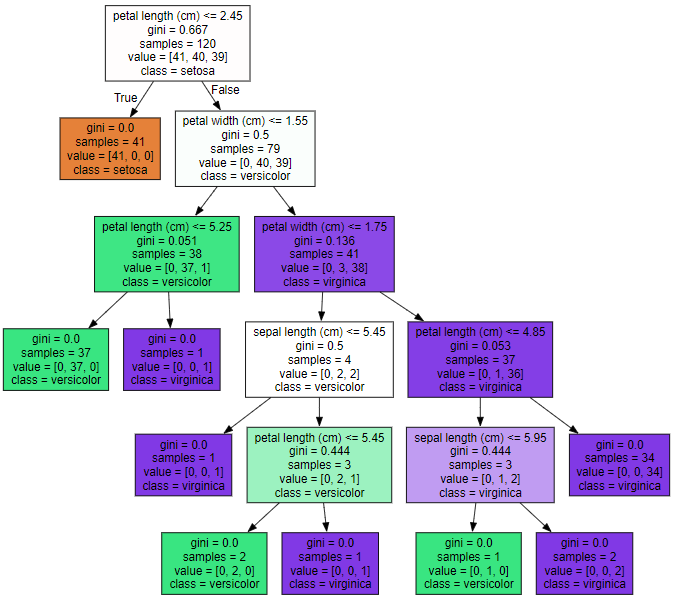
결정 트리의 장점
- 알고리즘이 쉽고 직관적이다
- 데이터 전처리 작업이 필요없다
결정 트리의 단점
- 서브 트리를 계속 만들다 보면 과적합으로 인해 정확도 떨어진다
→ 따라서 사전에 트리의 크기를 제한하는 것이 모델의 성능을 올리는데 도움이 된다
어떤 피처를 규칙으로 하여 분류를 할 것인가?
이를 위해 피처의 중요도를 알려주는 feature_importances_
- ndarray 형태로 값을 리턴하여 피처 순서대로 중요도가 할당
- 값이 높을 수록 해당 피처의 중요도가 높음
//사용예시
학습된 데이터.feature_importances_
//output 예시
[0.016 0.025 0.032 0.926]
//첫번째 피처의 중요도 0.016
//두번째 피처의 중요도 0.025
//세번째 피처의 중요도 0.032
//네번째 피처의 중요도 0.926
결정 트리 과적합(Overfitting)
- make_classification() 함수 - 분류를 위한 테스터용 데이터를 만들어준다
- 호출 시 피처 데이터 세트와 레이블 데이터 세트를 리턴한다
- 트리 생성 조건에 따라 달라지는 과적합 정도가 달라진다
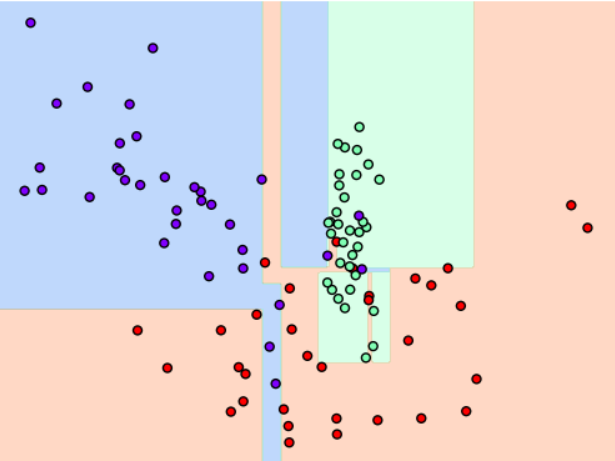
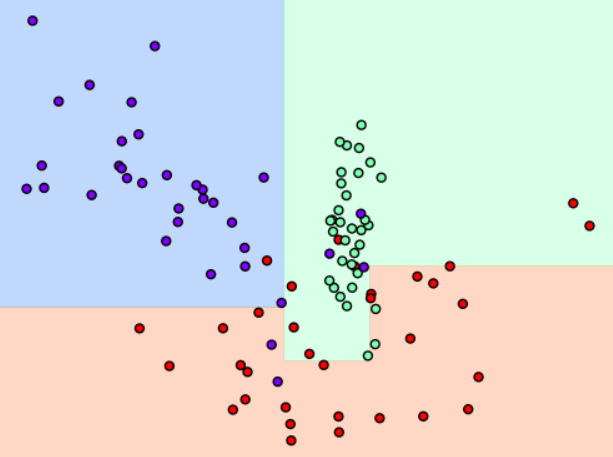
GridSearchCV
- 하이퍼 파라미터 max_depth를 이용해 결정 트리의 깊이를 조절할 수 있다
from sklearn.model_selection import GridSearchCV
params = {'max_depth' : [6, 8, 10, 12, 16, 20, 24], 'min_samples_split': [16]}
grid_cv = GridSearchCV(dt_clf, param_grid = params, scoring = 'accuracy', cv = 5, verbose = 1)
grid_cv.fit(X_train, y_train)
print('GridSeachCV 최고 평균 정확도 수치: {0:.4f}'.format(grid_cv.best_score_))
print('GridSeachCV 최적 하이퍼 파라미터:', grid_cv.best_params_)
- cv_results_ 속성을 통해 max_depth값에 따른 예측 성능을 볼 수 있다
# GridSeachCV 객체의 cv_results_ 속성을 DataFrame으로 생성
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
# max_depth 파라미터 값과 그때의 테스트 세트, 학습 데이터 세트의 정확도 수치 추출
cv_results_df[['param_max_depth', 'mean_test_score']]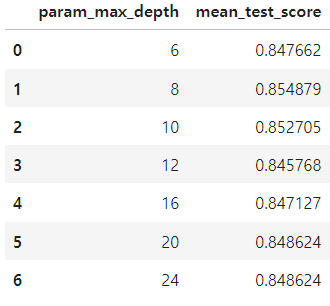
- seaborn을 통해 feature_importances_ 의 리턴값을 막대 그래프로 나타낼 수 있다
import seaborn as sns
ftr_importances_values = best_df_clf.feature_importances_
# Top 중요도로 정렬을 쉽게 하고, 시본의 막대그래프를 쉽게 표현하기 위해 Series 변환
ftr_importances = pd.Series(ftr_importances_values, index = X_train.columns)
# 중요도값 순으로 Series를 정렬
ftr_top20 = ftr_importances.sort_values(ascending = False)[:20]
plt.figure(figsize = (8, 6))
plt.title('Feature importances Top 20')
sns.barplot(x = ftr_top20, y = ftr_top20.index)
plt.show()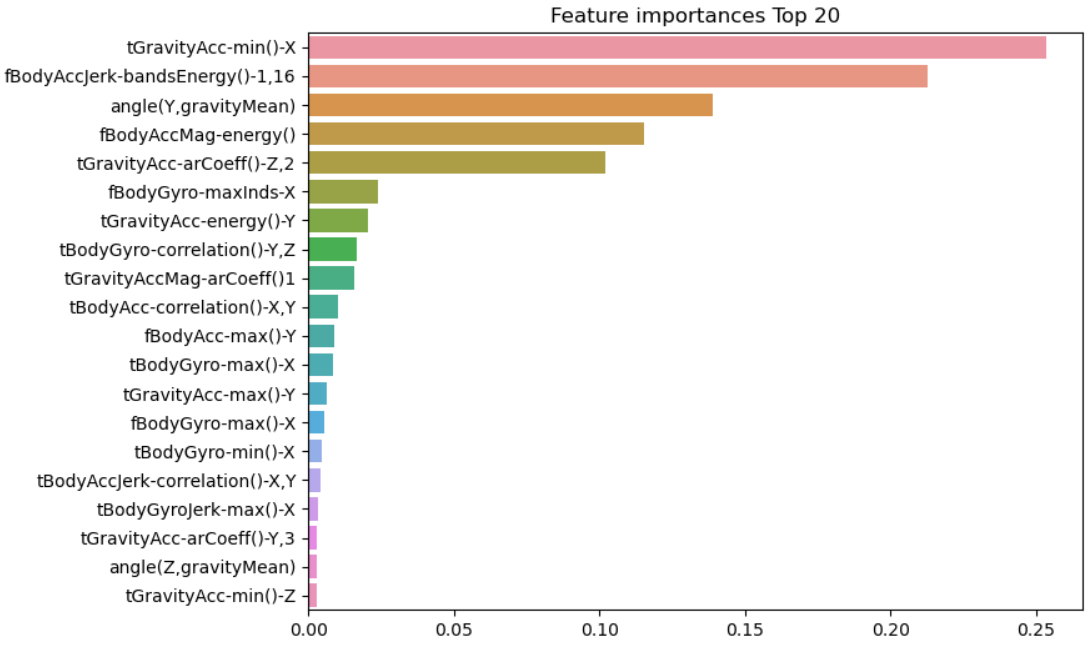
03. 앙상블 학습(Ensemble Learning)
- 여러 개의 분류기를 생성하고 그 예측을 결합해서 최종 예측을 도출해내는 기법을 말한다
- 정형 데이터 분류에서 뛰어난 성능을 가진다
- 랜덤포레스트와 그래디언트 부스팅 알고리즘 등이 있다
앙상블 학습의 유형
-보팅(Voting), 배깅 (Bagging), 부스팅 (Boosting)
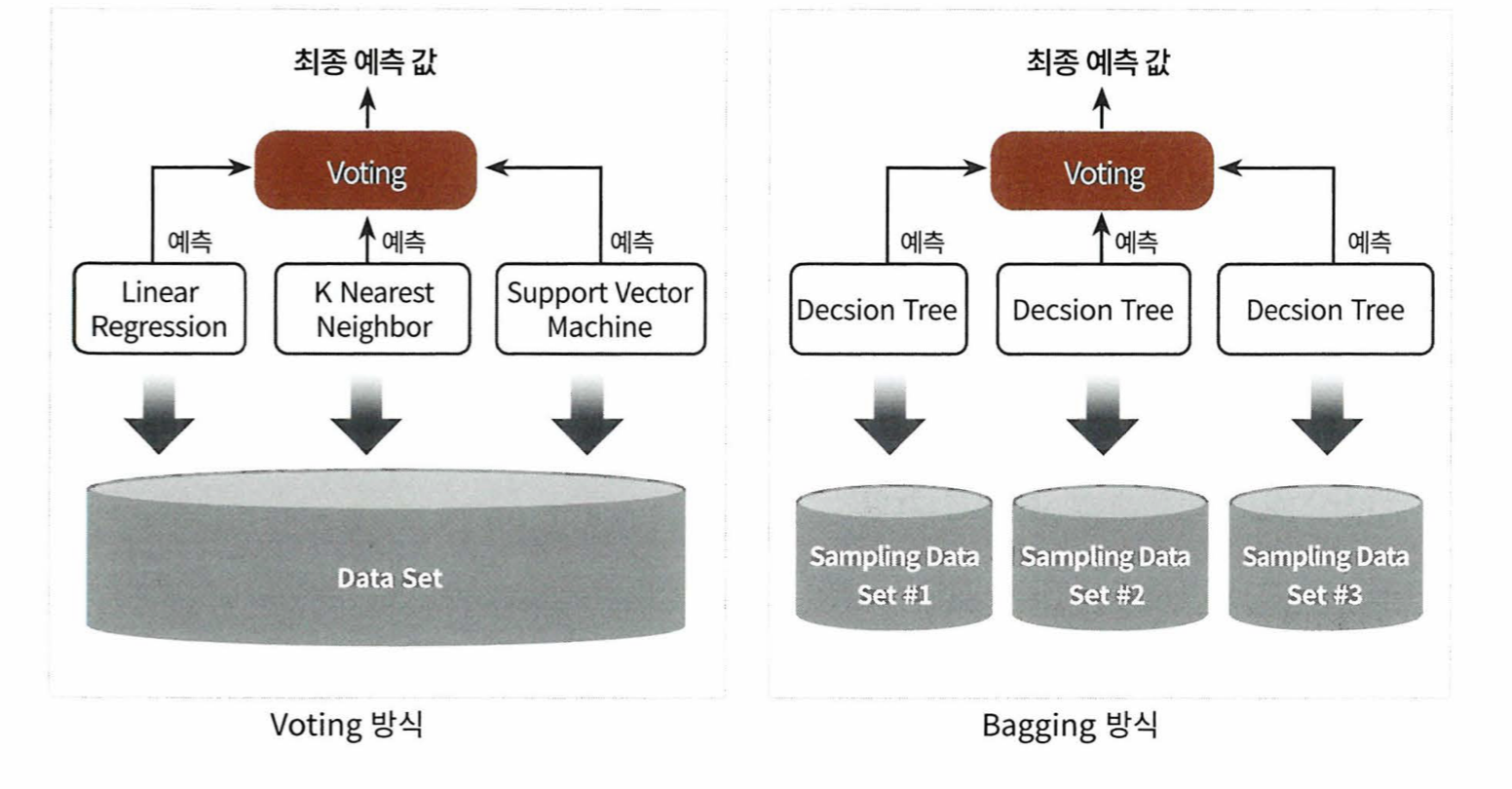
보팅
- 서로 다른 알고리즘을 가진 분류기를 결합하여 예측하는 것
- 하드 보팅과 소프트 보팅으로 나눌 수 있다
- 하드 보팅 = 분류기들이 결정을 내린 레이블 중에서 가장 많은 레이블을 최종 보팅 결과값으로 하는 것
- 소프트 보팅 = 분류기들이 결정을 내린 각각의 레이블에 대한 결정 확률을 모두 더해 평균을 내고 더 높은 평균을 가진 레이블을 최종 보팅 결과값으로 하는 것
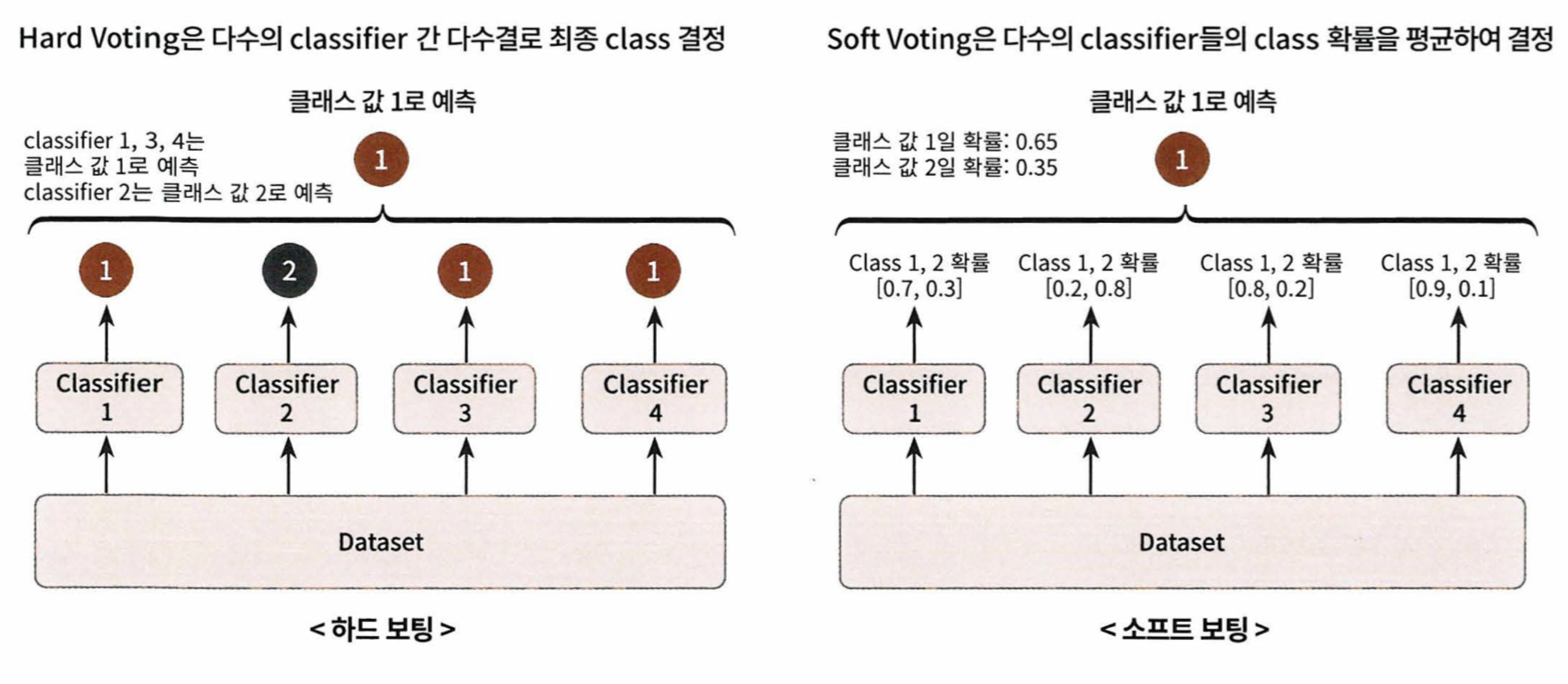
from sklearn.ensemble import VotingClassifier
VotingClassifier(estimators, voting)
//사용 예시 (로지스틱 회귀와 KNN 분류 모델 사용)
VotingClassifier(estimators = [('LR', lr_clf), ('KNN', knn_clf)], voting = 'soft')
vo_clf.fit(X_train, y_train)
배깅
- 같은 알고리즘을 분류기가 데이터 샘플링을 다르게 가져가 예측하는 것
- 개별로 데이터를 샘플링해서 추출하는 방식을 부트스트래핑(Bootstrapping) 분할 방식이라 한다
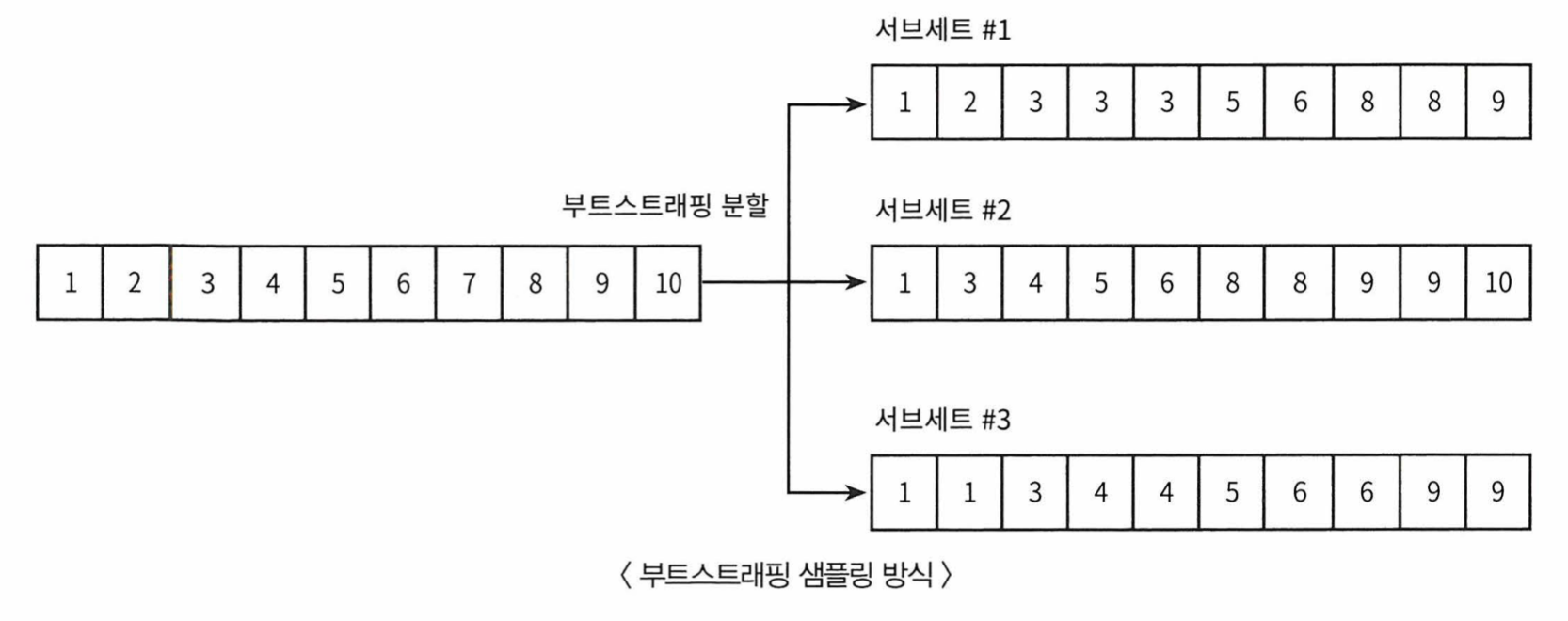
- 부트스트래핑의 준말이 배깅
- 샘플링된 데이터들 끼리는 중첩이 되어있다
- 배깅을 이용한 대표적인 알고리즘이 랜덤 포레스트
부스팅
- 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해서는 올바르게 예측할 수 있도록 다음 분류기에 가중치를 부여하는 것
- 계속해서 분류기에 가중치를 부여하기에 부스팅이라 부른다
- 대표적으로 그래디언트 부스트, XGBoost가 있다
04 랜덤 포레스트
- 배깅을 이용한 대표적인 앙상블 알고리즘
- 비교적 빠른 수행 속도를 가지고 있다
- 결정 트리를 기반으로 한다
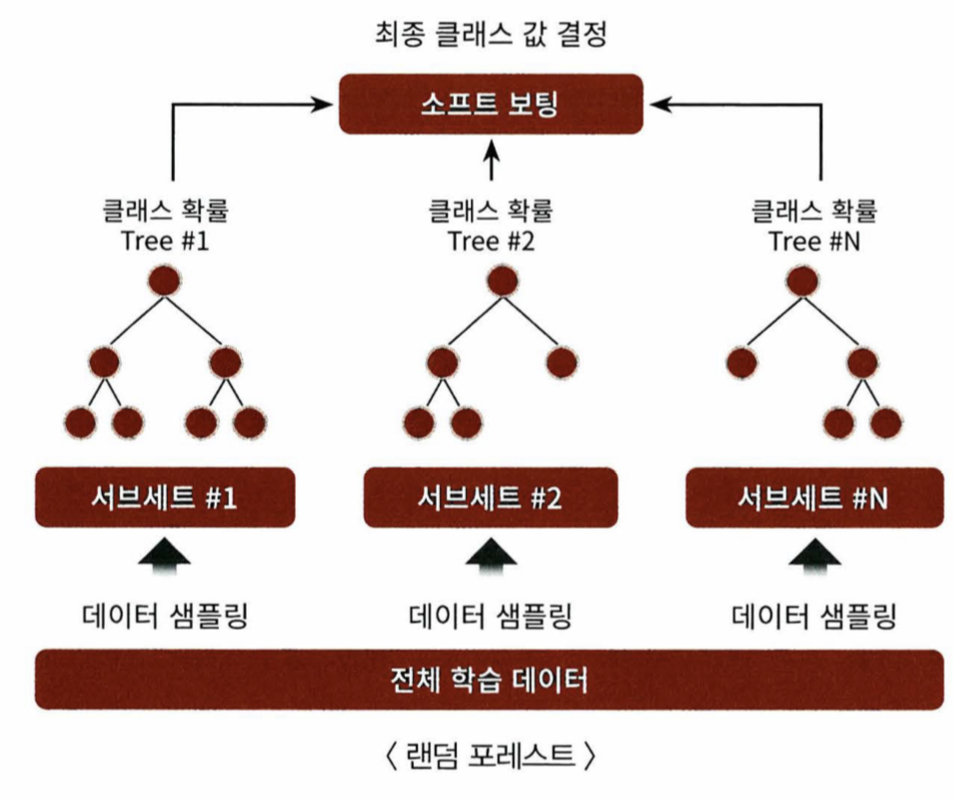
- RandomForestClassifier 클래스를 이용해 랜덤 포레스트 기반 분류를 할 수 있다
from sklearn.ensemble import RandomForestClassifier
RandomForestClassifier(n_estimators, min_samples_leaf, max_depth, min_samples_split, random_state)
//사용예시
rf_clf1 = RandomForestClassifier(n_estimators = 100, min_samples_leaf = 6, max_depth = 16, min_samples_split = 2, random_state = 0)
- 랜덤 포레스트의 하이퍼 파리미터들


- 마찬가지로 seaborn을 이용해 피처중요도를 막대 그래프로 나타낼 수 있다
'Study > 파이썬 머신러닝' 카테고리의 다른 글
| 파이썬 머신러닝 스터디 6주차 (ch06 차원 축소) (0) | 2024.05.08 |
|---|---|
| 파이썬 머신러닝 스터디 5주차 (ch05 회귀) (0) | 2024.05.04 |
| 파이썬 머신러닝 스터디 4주차 (ch04-2 분류) (0) | 2024.04.11 |
| 파이썬 머신러닝 스터디 2주차 (ch03 평가) (1) | 2024.03.28 |
| 파이썬 머신러닝 스터디 1주차 (ch01 넘파이와 판다스) (0) | 2024.03.23 |



